Code Project – JavaScript Pixel Camera
Sometimes I do projects that end up being entirely fruitless and pointless.
Ok, maybe not entirely fruitless, but sometimes I get caught up in an idea, and end up essentially just sort of, reinventing the wheel, in a complicated way. For starters, I got caught up with this little tutorial here: https://thecodingtrain.com/challenges/166-image-to-ascii . It uses JavaScript, to convert the input from your webcam, into ASCII art. It’s a nice little step by step process that really explains what is going on along the way so you get a good understanding of the process.
And I got it to work out just fine. I may mess with it and add the darkness saturation back in because it helps bring emphasis to the video but the finished product is neat.
I then decided I wanted to see if I could modify the code to do some different things.
Specifically, Instead of ASCII characters, I wanted it to show colored blocks, pixels if you will. I managed to modify the code, and the output is indeed a pixilated video, but it’s not video, it’s constantly refreshing text. The problem is, it’s writing out a page where every block, is wrapped in a <font> styling tag, which means it’s writing out a ton of extremely dense HTML code and pushing it out, so it’s a little weird and laggy and pretty resource intensive to run.
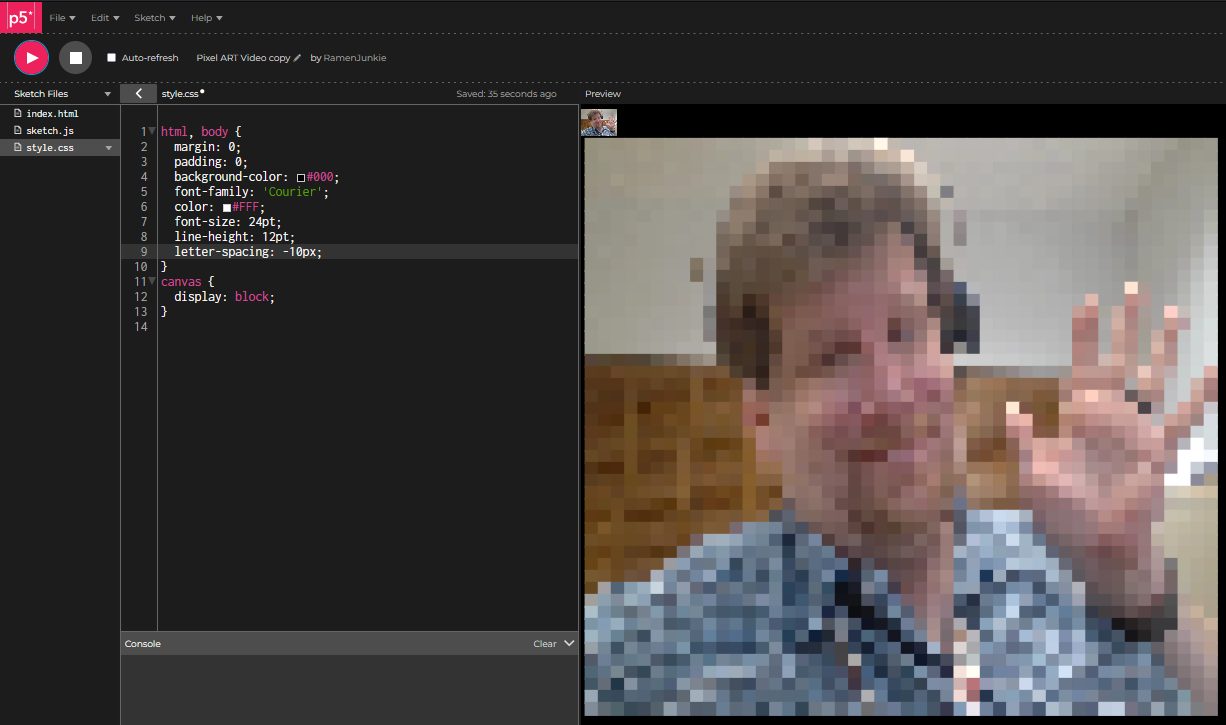
I also image, there is a way to simply, downsize the input resolution, and upscale the video, to achieve the exact same effect.
One variant I made also just converts images to single page documents of “pixels”. but, ugly font based pixels, to achieve an effect you can get by resizing an image small then large.
Like I said, kind of fruitless and pointless, but I got caught up in the learning and coding part of things.
I also may go ahead and do some additional modifications to the code to make things a bit more interesting. I could try using it to make my own Game Boy Camera style interface, for example. Then make it output actual savable pictures. I found a similar project to that online but it would be cool to code my own up and give it an actual interface.
Anyway, here is the code for the jankey video JavaScript, sketch.js first then index.html after. Also a Demo is here, though I may remove it int he long run, especially if I make an improve project.
let video;
let asciiDiv;
function setup() {
noCanvas();
video = createCapture(VIDEO);
video.size(48, 48);
asciiDiv = createDiv();
}
function draw() {
video.loadPixels();
let asciiImage = '';
for (let j=0; j < video.height; j++) {
for (let i = 0; i <video.width; i++) {
const pixelIndex = (i+j * video.width) * 4;
const r = video.pixels[pixelIndex + 0];
const g = video.pixels[pixelIndex + 1];
const b = video.pixels[pixelIndex + 2];
const pixelColor = "rgb(" + String(r) + "," + String(g) + "," + String(b) + ")";
// console.log(pixelColor);
// const c = '<font color=rgb('+r+','+g+','+b+')>'+asciiShades.charAt(charIndex)+'</font>';
const c = '<span style="color: '+pixelColor+';">◼</>';
asciiImage += c;
}
asciiImage += "<br/>";
}
asciiDiv.html(asciiImage);
}index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/1.6.0/p5.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/1.6.0/addons/p5.sound.min.js"></script>
<link rel="stylesheet" type="text/css" href="style.css">
<meta charset="utf-8" />
</head>
<body>
<main>
</main>
<script src="sketch.js"></script>
</body>
</html>
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.