Code Project – Python Flask Top Ten Movies Site
So, I mentioned dumping the Flask Blog a while back, but then I decided that since I had managed to get it all working, it would be somewhat trivial to get it working on a subdomain, instead of a main domain, which had been my original plan to start with. I was never too excited about dropping this project because I have a few ideas for little projects that I wanted to build that would actually work pretty well in Python and Flask, since it essentially adds a direct path to running a back end style script and a front in interface. Part of my frustration had come from trying to integrate OTHER Flask projects into the same website and Python code. Specifically the Top Ten Films website.
So I stripped out all of the work I had done on integrating the Top Ten movies site, and got the bare Blog running on smallblog.bloggingintensifies.com. That’s not a link, don’t bother trying to go there, there is nothing there (More on that in a bit). In this process, I got to thinking, I could run separate Flask Instances, one for each project, though I feel like that’s probably kind of super inefficient for server overhead. I went and did it anyway, with the Top Ten Movies site.
Which worked fine.
At this point, I realized, I had a working copy of this website to work with and test. A lot fo my previous frustration was adapting and merging two Python files, which share some redundancy, which share the same names on some secondary files and variables. I could now, modify the Top Ten Movies code, and test it, to remove the problem duplication. Satisfied, I shut off the Flask Blog, and merged the code again, and, it worked! Worked as expected. I did update the code a bit more again to add in the user/admin features of the Blog to the Movies page, so no one else can change the list.
I also changed the subdomain from smallblog.bloggingintensifies, to flask.bloggingintensifies.com. I mostly plan to use this sub domain to show off Flask Python projects, not just this blog I’m never going to fully utilize, so the name change makes more sense.
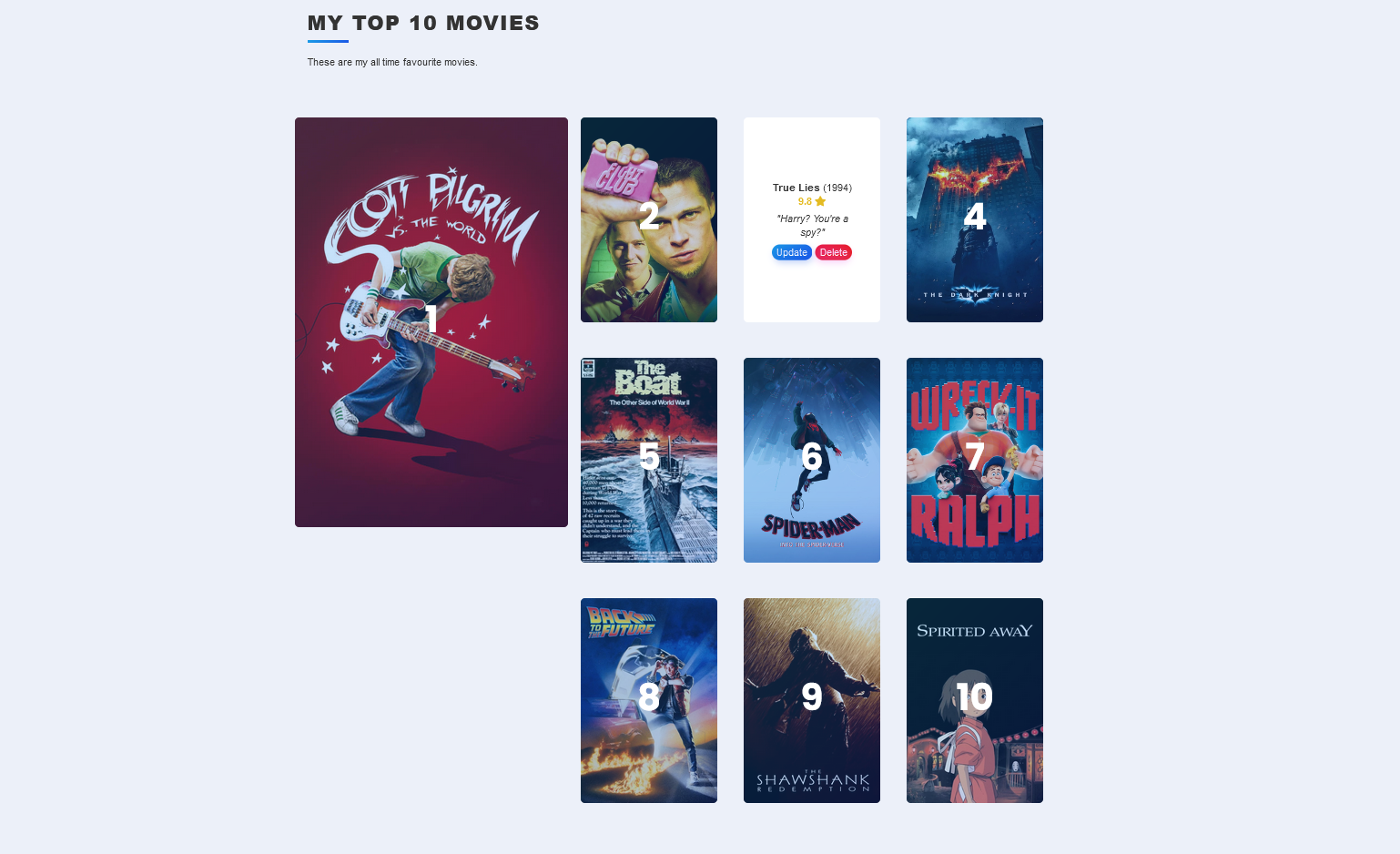
I also used some of the other HTML knowledge I’ve gained, well, the modern HTML knowledge, to reformat the Movie Site from how it was built in the class. The class just had a long single column with ten movies. I’ve changed it so number 1 is large and everything else is a smaller grid. It’s much prettier looking now. I doubt it changes much, if at all, but it’s a neat and fun project.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.

