I have been slacking on my posts, though technically still doing better than I had been. It’s a combination of being busy and just being generally meh overall. One think keeping me busy was re-mulching the flower beds around the house. Not just throwing down new mulch though, I mean raking up the old and putting down new weed barrier. This meant going around the existing plants and the little metal stakes to hold the weed barrier down were a pain because there is a ton of super packed rock in the area that makes them hard to insert into the ground.
In the case of the tree out back, it also meant digging up the ground around the tree to add a new flower bed space completely. We added a lot of new plants to the area as well, though most in pots for ease of use.
Then my wife put all her decor out again.
We also started working on the basic garden set up for the year. In the past we’ve had issues with trying to garden at this house because there is a lot of wildlife that comes around that eat or dig up everything. Right now it’s in buckets, though I plan to put legs on these wooden boxes we have to put the buckets into. Which is part of what the pile of wood behind the garden plants at the bottom is for. We also may use the stairs as a tiered herb garden. It’s all wood that was salvaged from my parent’s deck which they recently had replaced.
Anyway, here are some photos of the completed set up.
Here is a random bonus of the backyard from when I was mowing recently.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.
More often that it feels like it should, something in technology breaks or fails. I find that this can be frustrating, but often ultimately good, especially for learning something new, and forcing myself to clean up something I’ve been meaning to clean up. I have a Raspberry Pi I’ve been using for a while for several things as a little web server. It’s been running probably for years, but something gave out on it. I’m not entirely sure it’s the SD card or the Pi itself honestly, because I’ve been having a bit of trouble trying to recover through both. It’s sort of pushed me to try a different approach a bit.
But first I needed a new SD card. I have quite a few, most are “in use”. I say “in use” because many are less in use and more, underused. This has resulted in doing a bit of rebuild on some other projects to make better use of my Micro SD cards. The starting point was a 8 GB card with just a basic Raspbian set up on it.
So, for starters, I found that the one I have in my recently set up music station Raspberry Pi is a whopping 128gb. Contrary to what one might thing, I don’t need a 128gb card in my music station, the music is stored on the NAS over the network. It also has some old residual projects on it that should really be cleaned out.
So stuck the 8GB card in that device and did the minor set up needed for the music station. Specifically, configure VLC for Remote Control over the network, then add the network share. Once I plugged it back into my little mixer and verified I could remote play music, I moved on.
This ended up being an unrelated side project though, because I had been planning on getting a large, speedy, Micro SD card to stick in my Retroid Pocket. So I stuck that 128GB card in, the Retroid and formatted it. This freed up a smaller, 32GB card.
I also have a 64GB that is basically not being used in my PiGrrl Project I decided to recover back for use. The project was fun, but the Retroid does the same thing 1000x better. So now it’s mostly just a display piece on a shelf. Literally an overpriced paperweight. I don’t want to lose the PiGrrl configuration though, because it’s been programmed up to work with the small display and IO Control Inputs. So I imaged that card off.
In the end though, I didn’t end up needing those Micro SD cards though, I opted for an alternative option to replace the Pi, with Docker on my secondary PC. I’ve been meaning to better learn Docker, though I still find it to be a weird and obtuse bit of software. There are a handful of things I care about restoring that I used the Pi for.
Youtube DL – There seem to be quite a few nice Web Interfaces for this that will work much better than my old custom system.
WordPress Blog Archives – I have exported data files from this but I would like to have it as a WordPress Instance again
FreshRSS – My RSS Reader. I already miss my daily news feeds.
YoutubeDL was simple, they provided a nice basic command sequence to get things working.
The others were a bit trickier. Because the old set up died unexpectedly, The data isn’t easily exported for import, which means digging out and recovering off of the raw database files. This isn’t the first time this has happened, but its a lot bigger pain, which isn’t helped by not being entirely confident in how to manipulate Docker.
I still have not gotten the WordPress archive working actually. I was getting “Connection Reset” errors and now I am getting “Cannot establish Database connection” issues. It may be for nothing after the troubles I have had dealing with recovering FreshRSS.
I have gotten FreshRSS fixed though. Getting it running in Docker was easy peasy. Getting my data back, was… considerably less so. It’s been plaguing me now when I try to fix it for a few weeks now, but I have a solution. It’s not the BEST solution, but it’s… a solution. So, the core thing I needed were the feeds themselves. Lesson learned I suppose, but I’m going to find a way to automate a regular dump of the feeds once everything is reloaded. I don’t need or care about favorited articles or the articles contents. These were stored in a MySQL database. MySQL, specifically seems to be what was corrupted and crashed out on the old Pi/Instance because I get a failed message on boot and i can’t get it to reinstall or load anymore.
Well, more, I am pretty sure the root cause is the SD card died, but it affected the DB files.
My struggle now, is recovering data from these raw files. I’ve actually done this before on a surver crash years ago, but this round has lead to many many hurdles. One, 90% of the results looking up how to do it are littered with unhelpful replies about using a proper SQL dump instead. If I could open MySQL, I sure as hell would so that. Another issue seems to be that the SQL server running on the Pi was woefully out of date, so there have been file compatibility problems.
There is also the issue that the data may just flat out BE CORRUPTED.
So I’ve spun up and tried to manually move the data to probably a dozen instances of MySQL and MariaDB of various versions, on Pis, in Docker, on WSL, in a Linux install. Nothing, and I mean NOTHING has worked.
I did get the raw data pulled out though.
So I’ve been brute forcing a fix. Opening the .ibd file in a text editor gives a really ugly chuck of funny characters. But, strewn throughout this, is a bunch of URLs for feeds and websites and well, mostly that. i did an open “Replace” in Notepad++ that stripped out a lot of the characters. Then I opened up Pycharm, I did a find and replace with blanks on a ton of other ugly characters. Then I write up this wuick and dirty Python Script:
# Control F in Notepad++, replace, extended mode "\x00"
# Replace " " with " "
# replace "https:" with " https:"
# rename to fresh.txt
## Debug and skip asking each time
file = "fresh.txt"
## Open and read the Log File supploed
with open(file, encoding="UTF-8") as logfile:
log = logfile.read()
datasplit = log.split(" ")
links = []
for each in datasplit:
if "http" in each:
links.append(each)
with open("output.txt", mode="w", encoding="UTF-8") as writefile:
for i in links:
writefile.write(i+"\n")
Which splits everything up into an array, and skims through the array for anything with “http” in it, to pull out anything that is a URL. This has left me with a text file that is full of duplicates and has regular URLs next to Feed URLS, though not in EVERY case because that would be too damn easy. I could probably add a bunch of conditionals to the script to sort out anything with the word “feed” “rss”, “atom” or “xml” and get a lot of the cruft removed, but Fresh RSS does not seem to have a way to bulk import a text list, so I still get to manually cut and paste each URL in and resort everything into categories.
It’s tedious, but it’s mindless, and it will get done.
Slight update, I added some filtering ans sorting to the code:
# Control F in Notepad++, replace, extended mode "\x00"
# Replace " " with " "
# replace "https:" with " https:"
# rename to fresh.txt
## Debug and skip asking each time
file = "fresh.txt"
## Open and read the Log File supploed
with open(file, encoding="UTF-8") as logfile:
log = logfile.read()
datasplit = log.split(" ")
links = []
for each in datasplit:
if "http" in each:
if "feed" in each or "rss" in each or "default" in each or "atom" in each or "xml" in each:
if each not in links:
links.append(each[each.find("http"):])
links.sort()
with open("output.txt", mode="w", encoding="UTF-8") as writefile:
for i in links:
writefile.write(i+"\n")
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.
Sometimes I do projects that end up being entirely fruitless and pointless.
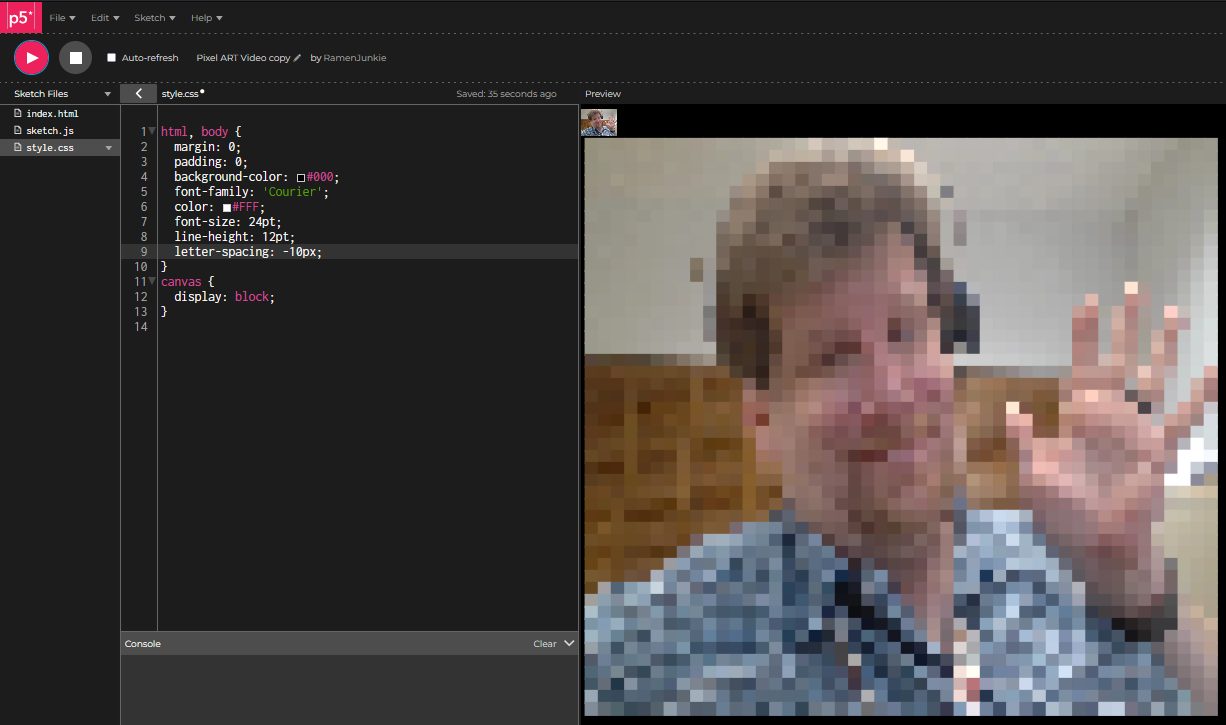
Ok, maybe not entirely fruitless, but sometimes I get caught up in an idea, and end up essentially just sort of, reinventing the wheel, in a complicated way. For starters, I got caught up with this little tutorial here: https://thecodingtrain.com/challenges/166-image-to-ascii . It uses JavaScript, to convert the input from your webcam, into ASCII art. It’s a nice little step by step process that really explains what is going on along the way so you get a good understanding of the process.
And I got it to work out just fine. I may mess with it and add the darkness saturation back in because it helps bring emphasis to the video but the finished product is neat.
I then decided I wanted to see if I could modify the code to do some different things.
Specifically, Instead of ASCII characters, I wanted it to show colored blocks, pixels if you will. I managed to modify the code, and the output is indeed a pixilated video, but it’s not video, it’s constantly refreshing text. The problem is, it’s writing out a page where every block, is wrapped in a <font> styling tag, which means it’s writing out a ton of extremely dense HTML code and pushing it out, so it’s a little weird and laggy and pretty resource intensive to run.
I also image, there is a way to simply, downsize the input resolution, and upscale the video, to achieve the exact same effect.
One variant I made also just converts images to single page documents of “pixels”. but, ugly font based pixels, to achieve an effect you can get by resizing an image small then large.
Like I said, kind of fruitless and pointless, but I got caught up in the learning and coding part of things.
I also may go ahead and do some additional modifications to the code to make things a bit more interesting. I could try using it to make my own Game Boy Camera style interface, for example. Then make it output actual savable pictures. I found a similar project to that online but it would be cool to code my own up and give it an actual interface.
Anyway, here is the code for the jankey video JavaScript, sketch.js first then index.html after. Also a Demo is here, though I may remove it int he long run, especially if I make an improve project.
let video;
let asciiDiv;
function setup() {
noCanvas();
video = createCapture(VIDEO);
video.size(48, 48);
asciiDiv = createDiv();
}
function draw() {
video.loadPixels();
let asciiImage = '';
for (let j=0; j < video.height; j++) {
for (let i = 0; i <video.width; i++) {
const pixelIndex = (i+j * video.width) * 4;
const r = video.pixels[pixelIndex + 0];
const g = video.pixels[pixelIndex + 1];
const b = video.pixels[pixelIndex + 2];
const pixelColor = "rgb(" + String(r) + "," + String(g) + "," + String(b) + ")";
// console.log(pixelColor);
// const c = '<font color=rgb('+r+','+g+','+b+')>'+asciiShades.charAt(charIndex)+'</font>';
const c = '<span style="color: '+pixelColor+';">◼</>';
asciiImage += c;
}
asciiImage += "<br/>";
}
asciiDiv.html(asciiImage);
}
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.
It’s been a bit since I really just wrote out a regular blog post so I thought it would be prudent to do so, mostly just touching on some of the stuff I’ve been doing or thinking about recently. I’ll just break things up a bit into some sections, for easy skimming/ignoring.
Old Writing
Every so often, I get this weird bug to just delete all of my old posts and start fresh and the old content all sucks and blah blah blah. Then that never really works out as hoped and I kind of miss having all the old content hanging around and I drag some of it back. Well, I’m currently in the “Dragging it all back” stage of things. Part of this is also part of my ongoing organizing of all of the shit I’ve written over the years.
I tend to get frequent “Project ADHD”. By the end of this blog post, that will definitely be very clear, but every time I have started to organize all of my old writings, or I just start a new method without pulling in old stuff, I’ve left a blob of “to get to” files. This applies to things not JUST writing, but the writing is particularly bad. I’ve got some that only show up in my blog archive hosted internally on my network. I have some files buried in “to sort” folders on a storage blob somewhere. I have several different folders in my own personal archive sorted using different methods.
These span different formats from Text to WordPress DBs to Doc files to even some old files I couldn’t open (I’ll touch on this in a bit). I’ve been converting it all to the new format, which basically falls into two major categories. i am sure I have said it about previous organizing attempts, but THIS is the way.
This is decidedly the way going forward. It’s been the way I WANTED to do things for a while, I just, wasn’t motivated enough to do it. The two over arching categories essentially amount to “Journal Entries” and “Structured documents”. Sorted into my One Drive Documents (for backup) as Journal and Documents. The Documents is sorted down into Reviews, by topic (video games, toys, etc), Original Fiction, Fan Fiction, Essays, and School. I’ll get to the School bit in a later section. The others are a bit more self explanatory, but generally, these are “longer form structured writing”.
Journal is everything else. This post, is being written into Journal, in a file called “2023.03.22 – On Recent Activities.md”, though that may not end up being the blog post title. This is the way. Everything starts in the Journal, with a date in the filename, because file system dates are incredibly unreliable, and then gets posted elsewhere, sometimes.
Ok, not everything starts there. Some of the Journal Entry documents start as Joplin Notes from my phone, because I’m not near a PC. Or they start as Reddit comments that end up going on long that I want to keep a note of later, where they get copy/pasted into One note, and later turned into Journal files. But, it is the ultimate repository.
I’ve been diligently converting old files to this format. Part of why I don’t just stick everything in there is that reviews often contain images, and the simple file format requirement of Markdown makes images a pain. Yes, Markdown can do images, but it’s much simpler in a Word Document. The issue in the past was that could mean I can’t open those Word Documents anymore in the future, but keeping things in One Drive helps stop that from being a problem, since everything these days is connected, and I have confidence that Microsoft will keep my documents up to date.
School Documents and Old Documents
Which brings me to the school documents. And as I said, “Documents that can no longer be opened”. A lot of my super old documents from the 90s, are in a Microsoft Works format, WKS or WPS. Word can’t open these. Notepad can sort of open them but they don’t have a proper format to them at all.
So I’ve collected these files up and spun up a Windows XP Virtual Machine. Thanks to Archive,org, I can get a copy of Microsoft Works from the 90s. I wanted to go really pure on the experience and run a Windows 98 VM, but I couldn’t get it to recognize the CD drive ISO to install Works, so Windows XP it was.
Fortunately, Works can save out .DOC files. They are Word 97 Doc files, and modern Word throws up a warning about them, but it can open them, and they are properly formatted, so that’s the goal. I also snagged an old copy of Microsoft Publisher from archive.org, to do the same with some ancient Publisher files. The modern Publisher Reader available online literally says “These files are too old and can’t be opened” when I tried that route. I also had some old CAD files, though those were able to be opened by the modern Autodesk Viewer. I kept the files, but I also did a bunch of print screens on each one to preserve them in an easier to view format.
I don’t really know why I need all of these old files, but file storage is cheap and they don’t take up a lot of space.
Lameazoid Rebuild
I started off with this as the first topic but rambled off into other areas, so I’ve moved it down here. As part of my organizing, I’ve been republishing, with, approximate original dates, a LOT of old content to Lameazoid.com. I pushed up like 100 old Video Game reviews. I have a few more movie and book write ups I’ve done on deck to do next. I am going to dig into old Toy content next, but I think there is less of that missing than other content.
Some of them are kind of trash they are so old, but honestly, despite calling them “reviews”, they are more just a “write up and record of my thoughts on whatever”. They are just, “Fancy journal entries with pictures”.
It’s all mostly for my reference.
Also, several of them are literal jokes. The Zero Wing review is written entirely in “broken English” like the Zero Wing game uses. I actually scrapped it, but I wrote a review of Morrowind once that was actually just bitching about how shitty the game’s performance was and all of the images were from Counter Strike, not Morrowind. Several are just an excuse to throw a bunch of funny screenshots on a webpage surrounded by text.
Things I WANT to Do
I also have a small list of things I want to do, that I’ve been mostly just, collecting resources for these potential projects. I’ve been increasingly looking into building some sort of simple games. Specifically, games for the NES or PICO-8. Throwing back to my “archive all the old things” writing above, I once made a Breakout Clone in Pico 8 on one my my CHIP computers but I can’t find it anywhere. And yes, I checked on the CHIP boards. It may still just be buried somewhere, I’ve actually found at least one large document project I had started on while sorting old files.
I also really want to do some Solo RPGs. This has been a bit of a growing trend I think online, or maybe I am just seeing it more since I gained some interest in it. A lot of these seem to amount to “Dice based story writing”, which is fine. I’ve actually done one or two of them, though a least one I decided was not for me and archived it off. I have a huge pile of Solo RPGs available through some ITCH.io bundles I’ve bought. I actually plan to blog about these once I do some that seem worth blogging about.
Things I Want to Do…. But I’m Not Doing Them
Just for the sake of throwing it out there, I also have other things I WANT to do that I have not been doing at all. I have a nice sketchbook that’s been sitting on a shelf nearby collecting dust because I really want to start drawing again. I used to draw a LOT but I have not at all, in years.
I still really want to learn to play the Piano, which I sort of started doing back in 2020 for a few months. But since then, the keyboard has just say dormant, next to my PC, as a silent reminder that I should be learning to play it.
I also still want to start cycling. I really need some sort of actual exercise outlet. I actually have an ok road bike I got a deal on at an auction, back in like, 2015 or something. I’ve ridden it like, twice, ever. I really need to get a proper helmet first. Which has been my excuse for not doing it. Another part of my hang up has always been that looking into online communities for cycling, it’s a group that is full of snobs, and that’s a huge fucking turn off. If you aren’t riding some $2000+ super bike then you’re completely wasting time and WILL get killed when it shatters into a zillion pieces after 3 rides. Like yo, you’re driving away anyone just trying to get into a new hobby.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.
This is one of those quick and kind of dirty projects I’ve been meaning to do for a while. Basically, I wanted a script that would scrape all of the top level comments from a Reddit post and push them out to a list. Most commonly, to use on /r/AskReddit style threads like, well, for this example, “What is a song from the 90s that young people should listen to.”
Basically, threads that ask for useful opinions on list. Sometimes it’s lists of websites or something. Often it’s music. The script here is made for music but could be adjusted for any thread. Here is the script, I’ll touch on it a bit in more detail after.
## Create an APP for Secrets here:
## https://www.reddit.com/prefs/apps
import praw
## Thread to scrape goes here, replace the one below
url = "https://www.reddit.com/r/Music/comments/10c4ki0/name_one_90s_song_kids_born_after_2000_should_add/"
## Fill in API Information here
reddit = praw.Reddit(
client_id="",
client_secret= "",
user_agent= "script by u/", # Your Username, not really required though
redirect_uri= "http://localhost:8080",
)
submission = reddit.submission(url=url)
submission.comments.replace_more(limit=0)
submission.comment_limit = 1
for x in submission.comments:
with open("output.txt", mode="a", encoding="UTF-8") as file:
if "-" in x.body:
file.write(str(x.body)+"\n")
# print(x.body)
The script uses praw, Python Reddit API Wrapper. A Library made for use in Python and the Reddit API. It requires free keys which can be gotten here: https://www.reddit.com/prefs/apps. Just create an app, the Client ID is a jumble of letters under the name, the secret is labeled. User Agent can be whatever really, but it’s meant to be informative.
The thread URL also needs filled in.
The script then pulls the thread data and pulls the top level comments.
I’m interested in text file lists mostly, though for the sake of music based lists, if I used Spotify, I might combine it with the Spotify Playlist maker from my 100 Days of Python course. Like I said before though, this script is made for pulling music suggestions, with this but of code:
if "-" in x.body:
file.write(str(x.body)+"\n")
# print(x.body)
It’s simple, but if the comment contains a dash, as in “Taylor Swift – Shake it Off” or “ACDC – Back in Black”, it writes it to the file. Otherwise it discards it. There is a chance it means discarding some submissions, but this isn’t precision work so I’m OK with that to filter out the chaff. If I were looking for URLs or something, I might look for “http” in the comment. I could also eliminate the “if” statement and just have it write all the comments to a file.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.