Code Project: VLC Portable Playlist to Text Dump
It’s kind of funny how one post can lead to another sometimes. This one is pretty basic but it also just shows a bit how useful I find knowing my way around computer systems to be. Yesterday I posted about my little annual music playlists. And as part of that, I wanted to actually post the playlist. I am pretty sure there is a fairly universal “playlist file type” out there and being open source, I had assumed that VLC on my phone stored the playlists somewhere in playlist files.
That assumption was wrong, it uses a .db file. A little portable database. There is an option to dump this file to the root of the phone, presumably for backup purposes, but it’s also useful to just browse it like I am doing here. The file itself can be opened and browsed with SQL Lite’s DB manager. It’s standard databases inside for tracks and artists and playlists.
Fortunately, I have had some experience dealing with database queries, so I set about building what was needed tog et the data I wanted. Pull the Playlist I want, in this case “2023 Best” but I could change that to do any available Playlist. This gives the tracks by id, but the tracks themselves are stored in a separate table for media. So that needs joined in. The media table stores track names, but not artist names, so an additional join is needed to get the artist names. This complicated things a bit because both the playlist table and artist table have a column “name” so more clarity needed to be added.
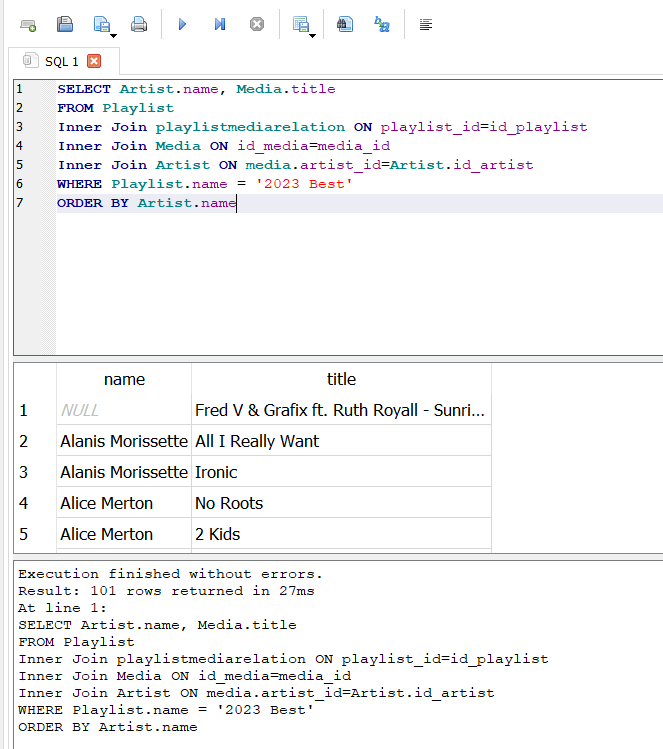
The result was this little query that dumps out a basic table of Artist and Song title.
SELECT Artist.name, Media.title
FROM Playlist
Inner Join playlistmediarelation ON playlist_id=id_playlist
Inner Join Media ON id_media=media_id
Inner Join Artist ON media.artist_id=Artist.id_artist
WHERE Playlist.name = '2023 Best'
ORDER BY Artist.nameNow, I could have done some cute clever trick now to merge the two into a new column and add in a ” – ” between but it was easier to drop it all into a notepad file and do a fine/replace on the weird space character that it stick in between the Artist and track title.
The added bonus here is I can easily use this query again anytime I want to dump a Playlist to text.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.