100 Days of Python, Projects 23-31 #100DaysofCode
In case anyone is keeping track (which they are not), you might notice that one, I’ve not been posting these posts in “real time”. I’ve been writing them later, after the fact. I kind of hope to change that. Also, I started on September 12th, and my last post was on September 28th, which is 16 days, though the last post went through Day 22. I’m actually moving faster than “100 Days” on my “100 Days of Code”.
This is intentional, I want to do Advent of Code again this year, starting December 1st. So I want to hopefully finish this up before December, so I am not overlapping these two daily level coding projects. I just, don’t have the time to do both. Based on my calculations, I need to get 18 projects ahead to end on November 30th.
Anyway, this round I want to wrap up the “Intermediate” level projects. This one may be a bit boring, just because it is a lot more “Basic Data Analysis” projects than “Cool Retro Game remakes”.
Day 23 – Turtle Crossing or Crossey Turtle
I was a little disappointed because the description sounded like this was going to be a “remake” of Frogger, only with Turtles. Instead it’s a remake-ish, of Crossey Road. Which is slightly less exciting. I feel like I could probably make my own Frogger, and I will probably put that on a ToDo list somewhere to forget about because all my ToDo lists are 1000 items long….
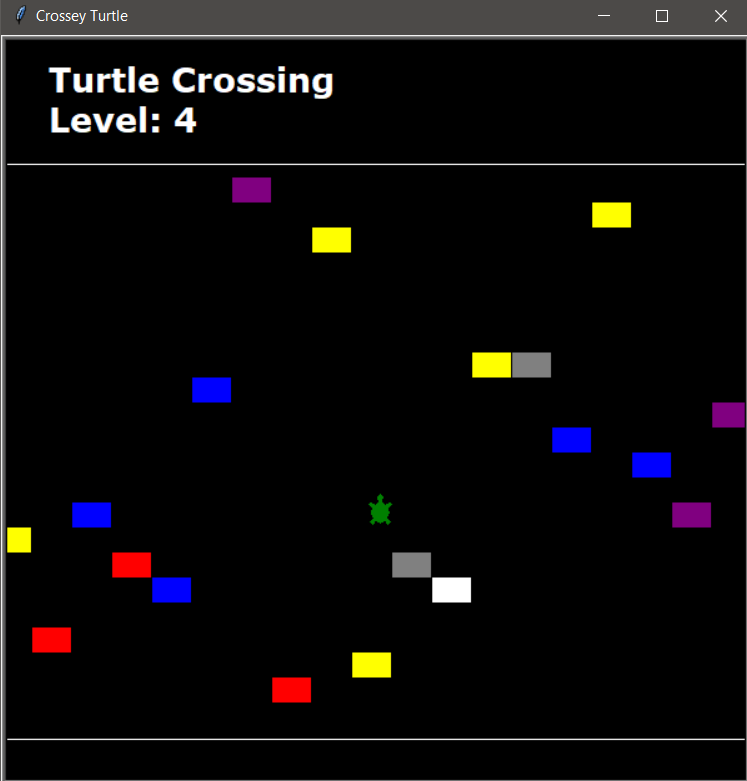
Anyway, the job is to get the turtle across by avoiding the cars, which randomly spawn on one side of the screen. Each time the turtle makes it, the cars start moving slightly faster. It was an interesting project to develop, and like Snake, I cleaned it up a bit from the instructor’s code by aligning the cars and turtle to lines. The main this this does it helps to remove the ugly overlap with a pure random spawn. I considered adding some code to stop them from spawning on top of each other in the same line but decided I didn’t care enough to bother.
The trickiest part of this was adjusting the delays and spawn timer so things felt right. With a spawn timer too low, then cars were just pouring out. With it too high then the road is just wide open. Another issue I had briefly, when the cars would speed up, only the currently on screen cars would speed up, everything new would still run slow.
In general I don’t really care for this game, primarily I think because the game actually gets easier the faster the cars get because the gaps become huge and easy to pass through. It could be adjusted a bit probably to spawn more cars at higher speeds which may fix this.
Day 24 – Improved Snake Game and Mail Merge
Today’s lesson had to do with file I/O. I’m actually already pretty familiar with this, a lot of the scripts I have written in my free time take a file in, manipulate the data in some way, and spit a file out.
Step one was to modify the Snake Game to have a persistent high score written to a file. Which was neat.
The second was a simple Mail Merge exercise. Take in a letter, take in a list of names, output a series of letters with the names inserted.
Day 25 – US State naming Game
The exercise today was an introduction to Pandas, which is a tool that makes working with large data sets much easier. In the first round of practice, we pull data from a large csv of Squirrel Data and count Squirrel Colors from here: https://data.cityofnewyork.us/Environment/2018-Central-Park-Squirrel-Census-Squirrel-Data/vfnx-vebw which was silly and fun.
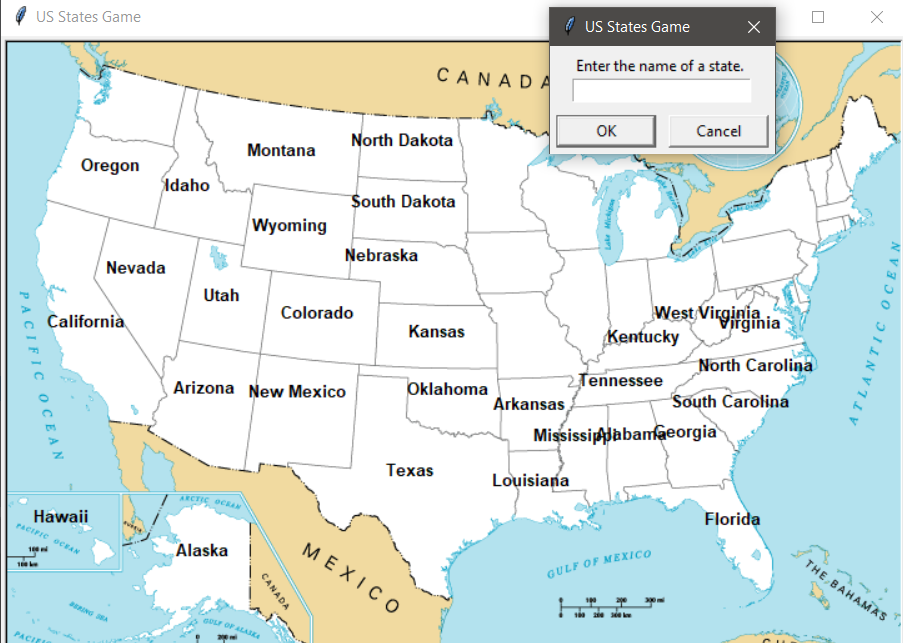
The second was a little learning game where the player names states of the United States. Each correct guess shows on the map. When you type “Exit” you get a file back of which states were missed. One of the interesting things here was adding a background image to the Turtle Screen. I also tried to build it in a way that it would be easy to say, swap out the background image and data set for European Countries, or anything similar.
On a total side note, I got all 50 states on my first try. I am pretty sure I know all the capitols still as well.
Day 26 – List and Dictionary Comprehension and NATO Alphabet Translator
Probably one of the quickest programming days but longer lessons page with several simple exercises. It also felt like one of the more “necesary in the long run” lessons. Basically, the whole lesson was about better ways to iterate through data. Single line codes like “list = [item for item in other_list]”.
The end project was very short, pull in a CSV of NATO Phonetics using Pandas, then one line iterate it into a dictionary. Ask for a user input, loop through the user input to make a list of words, output the list.
Day 27 – Miles to Kilometers Conversion Project and TKinter
So on the surface, a Miles to Kilometers converter isn’t that exciting. In fact, it’s a straight forward multiplication/division that even the most beginner level coder could whip up. The point of this lesson was more of an introduction to TKinter.
The end result is a little window based converter, that in my case, goes both ways, so you can do Miles to KM or KM to Miles, which is probably boring but wasn’t part of the requirement for the project.
Day 28 – Pomodoro Timer
The object of this lesson was to build a Pomodoro Method Timer. I don’t super follow “productivity” methods but I guess the Pomodoro Method is to use a timer, work for a period, take a short break, repeat this pattern a few times, then take a longer break. I don’t know if these times are set in stone, but for the project we used 25 minutes of work, 5 minutes of break, repeated 3 times, and then 20 minutes of long break.
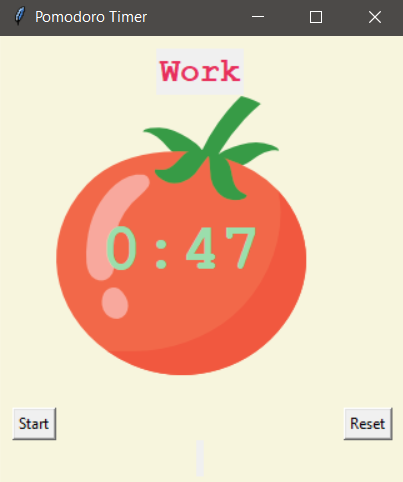
The actual lesson here is how to create a TKinter window that is “constantly running”. While able to take some input, and manipulating various bits of the UI. It counts down a timer, it adds check marks every round, it had a start and reset button.
This one was actually pretty tricky, and I kept ending up with essentially several layered running timers because I was using the window.after function improperly at first. Otherwise it’s just a loop that runs through some conditionals to see where it’s at in the loop. I did manage to do like 90% before watching the videos, but it took me an extra session of code work to puzzle it out. The one bit I wasn’t sure on was how to make the Reset button actually top the timer loop, which wasn’t complex, but I did have to get that one from the class.
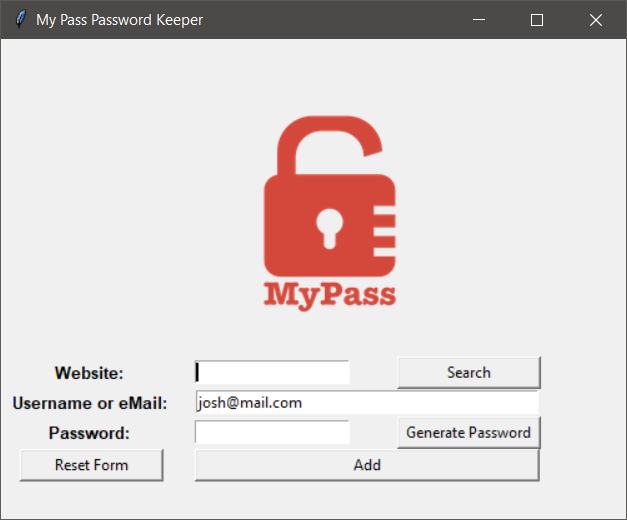
Day 29 – Password Manager Part 1
So, I really liked this project, and I need to find out how to make exe files out of these pieces of code. I actually would definitely use this project regularly, especially after adding some additional features, which may in fact come in tomorrow’s part 2. This was also another project that I essentially completely built before actually watching the lessons. Which I suppose means the previous lessons on how to use TKinter worked well. I will say, the most annoying part of TKInter is just how finickey the positioning can get, The instructor likes using Grid() to place but personally, I think I like using Place(), but the problem is, I could get caught up tweaking Place() for hours.
This project so far has combined several previous projects, from the Password Generator, to using TKinter, to writing output files. I suspect tomorrow will add in even more with Reading Files, and working with “organized data” in the process. I could also see using Ciphers to actually encrypt the output data file to something that’s not readable without a master password.
My favorite part was revisiting the “Password Generator” code created back on Day 5. In addition aot simplifying it with some list comprehension, I also converted it to be an Object Oriented Class, that could be imported and called. Not super difficult but I still felt pretty proud of that one. It doesn’t really add a lot of benefit, but it was more just an exercise for my own ability. I also made it easy to change the default email address by putting it in a separate config style file that I may work with more later.
Day 30 – Password Manager Part 2
Most of this day’s lesson was using error handling, specifically, “try:”, “except:”, “else:” and “finally:”. I kind of figured there was a better way of handling “random errors” than painstakingly considering every option, but I’ve never really had a need to look into it too super deeply. Usually for error handling, I’d just stick an “if” into a loop, and if the “if” fails, it just keeps looping until the input is good.
I did this a lot early on, on my own accord, for many of the text inputs. I would make an array of “valid entries”, often something like:
valid = [“yes”, “y”, “no”, “n”]
while answer not in valid:
answer = inout(“Yes or no?: ).lower()
Which honestly is probably still plenty valid for small choice selections.
I was a bit disappointed that the end result didn’t even make a token attempt to encode the output data, storing passwords in plain text is a really really really really really really bad idea. Oh well, future project.
All in all, this is definitely the most complex project so far, and it’s possible the most complex single project I’ve done ever code wise. I’ve done some elaborate PHP/HTML/CSS web stuff, but those were always more, ongoing projects with sub-projects tacked on to them.
Day 31 – Flashcard App
Another one that I definitely will use once I make it work in a stand alone fashion in the future. This app was quite a bit simpler than the Password Manager but I’ve found that so far, at the end of each section, there has been a complex capstone project, then a few simpler ones. The bigger purpose of this project was learning to manipulate JSON and CSV data better, in addition to making a simple GUI.
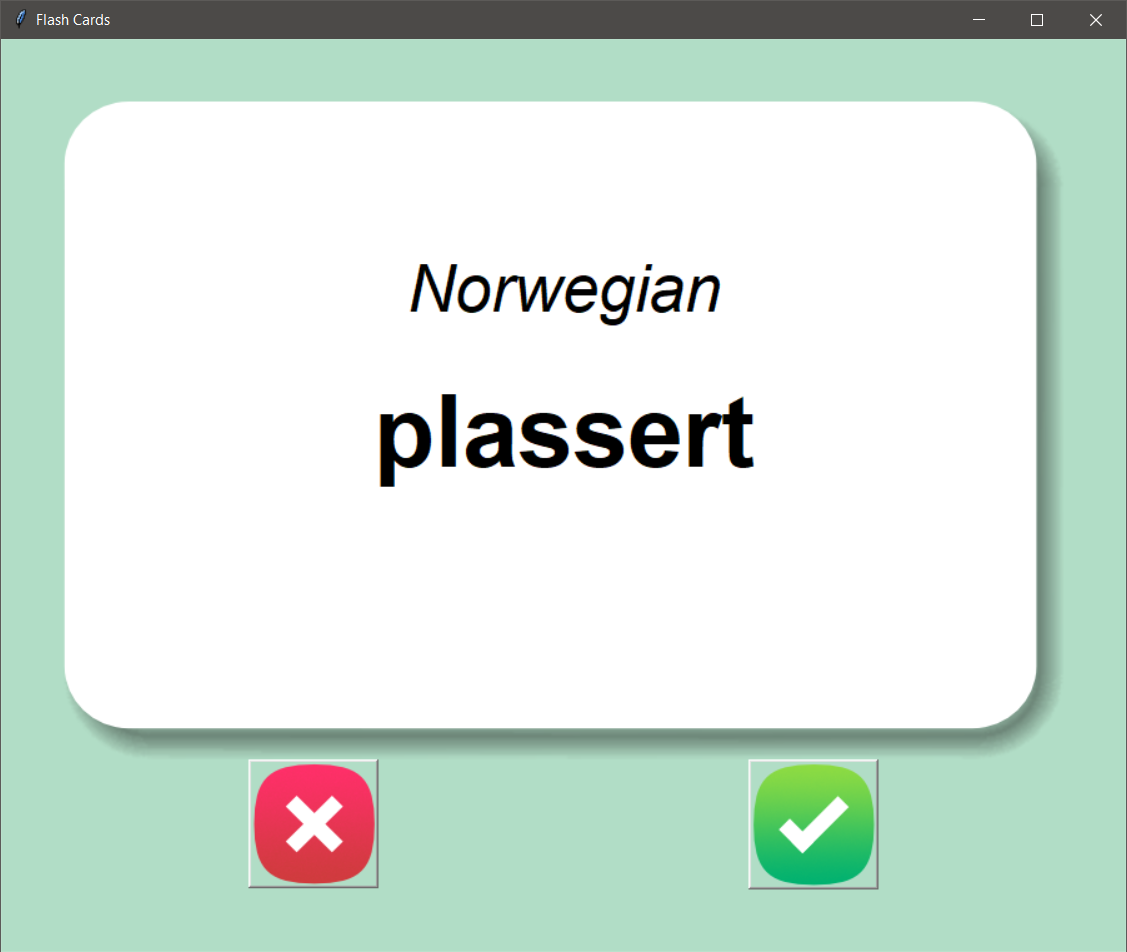
This app reads some data in, in this case, language words, but it could be any set of data. Then it shows the foreign word, for three seconds, before showing the English word. If you guessed it correctly, you hit the green box, it not, hit the X. It’s kind of an honor system thing, but if you are trying to learn a language, why would you cheat yourself like that.
It also removes “learned words” from the pool of possible cards, permanently. Well, or until you reset it by deleting the save files.
I’ve written a few times about my goal to learn some languages besides English by 2030. I’ve gotten alright at Spanish, and I’ve been working on Norwegian. The class provided a word bank for French but also explained how to make your own word bank, which I did. Making a new word bank was not required, but I know absolutely zero French, and it was hard to tell if the cards were accurate. So I built a Norwegian Word Bank, and will definitely build a Spanish one. The only problem is, I went with the “Top 10,000 words”, and you only really need the “Top 2-3000 words” to start grasping the language. So my custom word bank helped, but not as much as it could have, because I started getting some really lesser used words. It’s easy enough to trim it off though, I can just open the data file and delete the bottom 9,000 lines.
And so this wraps up the “Intermediate” lessons. The next session is “Intermediate+”. Based on the daily topic headers, it looks like this next section is going to delve way deeper into using APIs to gather and manipulate web services, which should be a lot of fun. I’m definitely learning more and I plan to revisit some of my own personal projects to make them much better once I’ve finished with the course. A lot of my old data manipulation involved lists and a lot of if/else statements inside for loops. Which is messy, and probably slow. A lot of the new tools I’ve learned will really help.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.