My Music Listening Habits for 2020
Yeah, those monthly updates were kind of bleh, so I dumped them. But I still want to do a yearly wrap up. Though overall there isn’t a lot that’s surprising to me about the yearly stats.

The year was dominated by most of the artists I would expect it to be dominated by. Sigrid, Tessa Violet, Aurora, CHVRCHES have 14 of my top 25 albums. This grid doesn’t even include a few additional Sigrid “Albums” of live tracks that don’t properly show up so they get filtered.
Anyway, a bit better breakdown…
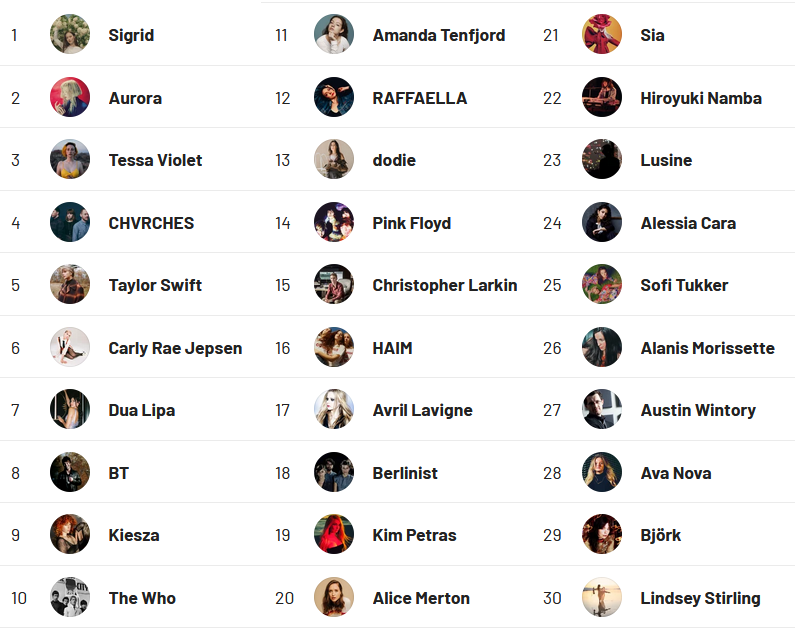
I am actually surprised that Sigrid still topped the chart above Aurora. I’ve been listening to a TON of Aurora, and not just “recently” or something, like all year. Plus Sigrid hasn’t had anything new since November 2019, so I felt like I had been listening to her music less. I still had around 100 more scribbles on Sigrid than Aurora. Tessa Violet, I’m less surprised about. I’ll comment a bit more later, but Tessa Violet has kind of dominated my individual song listens, she just… has less songs.
CHVRCHES has been kind of slowly building up more and more in rotation, and I expect them to continue to come in pretty high going forward as well. Another sleeper to look out for next year will be Dodie, at number 13. She only has a handful of tracks, and I’ve only recently started listening to her, but I really like her music, and next year, she has her first full album coming out.
On the “falling” list, I’ve hardly been listening to Alice Merton and Kiesza lately. Nothing wrong with either, they just sort of, have fallen off the rotation. And despite both ranking high, Dua Lipa and Carly Rae Jepsen were never really in the rotation. I’m honestly not sure how either is so high.
There are also a few of my more mainstay artists making a showing. The Who, BT, Pink Floyd, Avril Lavigne, Alanis Morrisette, Taylor Swift. I’m a little sad that Raffaella only really had one new song recently. She was the opening act for Sigrid when I saw them in 2019 and I really like her music. She has put out one track, Bardot, and a collaboration track called On the Look Out, that may as well just be a Raffaella track.
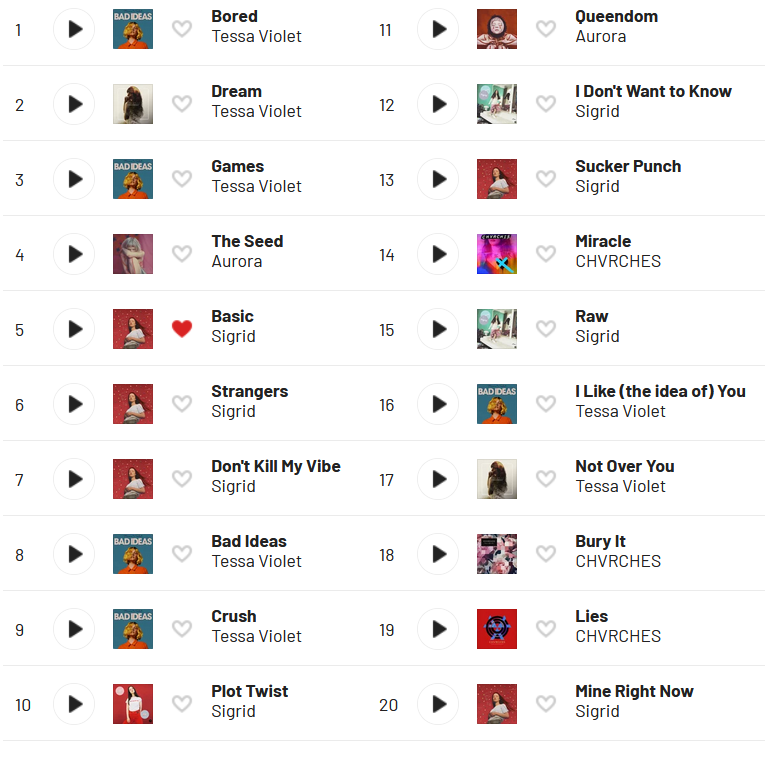
My single top track for the year, is, without question, the “2020 Anthem” of Bored.
Granted, this track is older than 2020, but it got a music video in 2020, and it kind of just sort of… fits the feel.
Half of my top ten were Tessa Violet tracks, so like I said, she kind of dominated on an individual track list. Everything else is about as expected, though I would have thought more Aurora tracks would have made the cut for that top 20.
Anyway, if you want, you can always just follow me on Last.fm.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.





