Code Project: Network Map Webpage, Making it Better
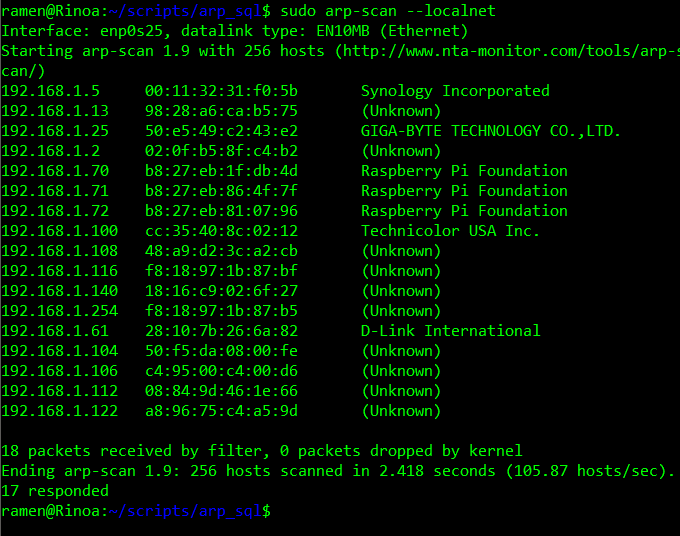
I wrote a bit about my Network Map Webpage recently. It’s part of a larger home dashboard project I’m working on, but as part of that I’ve updated things a bit to make them more streamlined and easier to use. The biggest problem with the page as it was originally coded is that it shows everything. I’ve cycled most of my regularly used electronics onto the network so they could be captured by an arp scan, though not all of them are on all the time. For example, I still have a Raspbery Pi and Arduino set up to capture temperature data. I also have several Next Thing CHIP devices, though Next Thing has gone out of business. In total, between my IOT stuff and laptops, phones and tablets and the duplicate IPs from the network extender, I have 55 devices in the raw table.
So I set out to make this more manageable at a glance. My original query in my PHP code looked something like this:
SELECT ip, arpscans.mac, arpscans_known_macs.device_name, arpscans_known_macs.device_description, last_seen, device_owners.user_name FROM arpscans LEFT JOIN arpscans_known_macs on arpscans_known_macs.mac = arpscans.mac LEFT JOIN device_owners on device_owners.id = arpscans_known_macs.device_owner ORDER BY ipBy slipping in “WHERE last_seen >= NOW() – INTERVAL 5 MINUTE” just before ORDER BY, I can make the code return only currently connected devices. The ARP scan runs every 5 minutes, anything that has a last seen time stamp within 5 minutes is assumed to still be attached. This interval could be shorted to almost real time, but I don’t really need that much of a check.
I can also view all disconnected devices with a simple change of the above command, making it “WHERE last_seen <= NOW() – INTERVAL 5 MINUTE”. This wouldn’t work if I were still keeping historical data, but I essentially only capture the last seen data for any device. Essentially what this does is return everything not seen in the last 5 minutes.
I also broke out my PHP code that builds my table from my query into it’s own PHP function. This was I could set the variable $SQL for the active devices, call the function to build the table, then set $SQL for inactive devices and build a second table, under the first.
I immediately scrapped this, because it was ugly. Plus, sometimes I do want to see “everything”.
Enter some GET calls and an if/else statement.
if($_GET['show'] == "active") {
// SQL for selecting active devices
$tabletitle="Active Devices";
$sql = "SELECT ip, arpscans.mac, arpscans_known_macs.device_name, arpscans_known_macs.device_description, last_seen, device_owners.user_name FROM arpscans LEFT JOIN arpscans_known_macs on arpscans_known_macs.mac = arpscans.mac LEFT JOIN device_owners on device_owners.id = arpscans_known_macs.device_owner WHERE last_seen >= NOW() - INTERVAL 5 MINUTE ORDER BY ip";
}
elseif($_GET['show'] == "inactive") {
// SQL for selecting active devices
$tabletitle="Inactive Devices";
$sql = "SELECT ip, arpscans.mac, arpscans_known_macs.device_name, arpscans_known_macs.device_description, last_seen, device_owners.user_name FROM arpscans LEFT JOIN arpscans_known_macs on arpscans_known_macs.mac = arpscans.mac LEFT JOIN device_owners on device_owners.id = arpscans_known_macs.device_owner WHERE last_seen <= NOW() - INTERVAL 5 MINUTE ORDER BY ip";
}
else {
// SQL for Selecting all devices
$tabletitle="All Devices";
$sql = "SELECT ip, arpscans.mac, arpscans_known_macs.device_name, arpscans_known_macs.device_description, last_seen, device_owners.user_name FROM arpscans LEFT JOIN arpscans_known_macs on arpscans_known_macs.mac = arpscans.mac LEFT JOIN device_owners on device_owners.id = arpscans_known_macs.device_owner ORDER BY ip";
}Basically, if nothing, or a random string is passed by the URL variable “show”, then it goes to the end, and displays everything when accessing the page at index.php. If it passes index.php?show=active, it sets $SQL for showing active devices and if it gets index.php?show=inactive, it shows inactive devices. It also sets a variable called $tabletitle which is just echoed out into some header tags. I then added links across the top of the page to each of these filters.

This allows for a quick and easy toggle of which data is pulled and displayed.
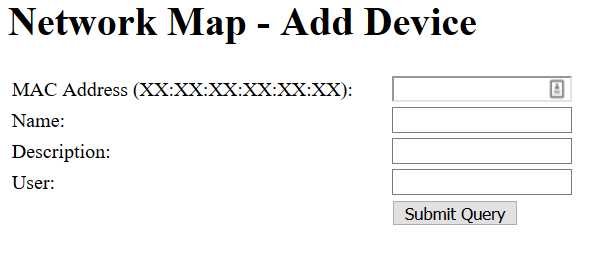
Additionally, I updated the way the Add Device form works. Previously, the form would fill in the MAC, a Device Name and a Device Description, then it would POST to another PHP page that would insert the data into the table, then forward on back to the index page with a header redirect. I’m not going to get into too much detail on it here, but I also integrated the Network Map into my dashboard framework with a header, navigation, sidebar, and footer. It also uses a table based navigation system, so in order to view the network map, I am hitting “index.php?page=4”. Pages basically all need to be wrapped in this structure to work properly, so in order to make things flow better, the Add Device form now POSTs back to the Network Map page itself, which checks to see if the POST variables are set, and if they are, it inserts the new information, before pulling the table.
This also meant slightly altering my page calls to look for “index.php?page=4&show=active” and “index.php?page=4&show=inactive”.
Eventually I want to move the Add Device form to appear at the top of the page, so the whole thing is all handled in one single page.

Lastly, I made up a quick block of code in it’s own page, that simple counts and displays the number of currently connected devices on the network. This block is embedded on the front page of my Dashboard Framework and links to the full Network Map page. The general idea on the Dashboard is to have widgets like this that show quick glance information, with links to detailed information.

I have not built a lot of them yet, but one of the others I have built works somewhat similar to the ARP scanning system. A script makes a call to my TT-RSS instance for each of the segmented accounts I have, then dumps the unread count into a table on the server. The widget shows how many unread articles each topic/account has. I am still really bad about only actually reading the Basic feed (mostly Toys and Video Games).
But I will get into the Dashboard Widgets thing a bit more in a future post probably.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.