The Writers and Actor’s Strike
I generally don’t comment much on Next Door, a lesser known, location based social network. Most of the posts are dumb, but not worth really arguing. I did see this image, somewhat randomly posted, and did comment, and I’m going to expand on the idea of my comment here. I also don’t know why they bothered posting it. The whole point of Next Door is “local discussion”, not stupid Macro politics discussions.
For a few weeks or so, there has been a writer’s strike in Hollywood. This isn’t the firs tone, it’s probably not the last, these people also really seem to know how to at least put an effort into their demands. Recently, a day or so ago, the actors union joined in the strike. Hollywood is effectively at a stand still. Expect another boon in shitty reality TV like back in the 2009 time frame.
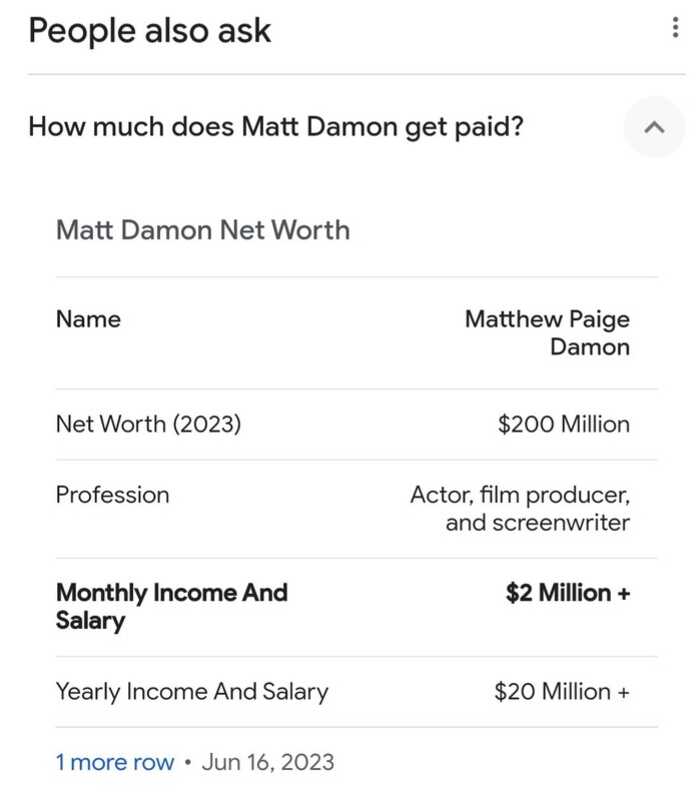
This graphic feels like some sort of “clever gotcha” about rich Hollywood stars, singling out Matt Daemon. Does he make too much money for his films? Eh, probably. Of all the “rich people” in the world, I really find it hard to get too upset over movie and music star millionaires. There’s a lot of reasons for this, but it basically joint boils down to, a lot of them tend to actually support philanthropic causes, and their star power creates a draw and work for a LOT of other people. Also once reaching “star level”, especially Matt Daemon star level, there tends to be a lot of extra baggage and upkeep needed, nice clothes, an expensive security detail, etc. I’m not saying at the end of the day Matt Daemon is poor, I’m just saying, his 2+ Million months income, probably has a pretty heft amount shaved off for “Monthly expenses” that most people do not have.
He still probably makes too much money, but he also isn’t going around doing shitty things and promoting hate groups online.
Anyway, the bigger issue is, that 90%, probably more, of “Hollywood” isn’t anywhere near Matt Daemon. They are probably way less than “most people” in terms of income. Using these big stars for reference is stupid. The strike isn’t about Matt Daemon, it’s about Ryan Rathbun, Jack Wang, and Ansa Woo. Who are these people? Who knows? I pulled them off of IMDB from Daemon’s most recent film Oppenheimer, they are “Lecture Attendee,” “Cambridge Student,” and “Female Student #70” respectively.
They are all listed as “Uncredited”. But they did still, do work, they still got paid. I have no idea what the pay rate for “Female Student #70” is, but I am sure it’s not $20+ Million a year.
So ok, there’s some angle I suppose, maybe Matt Daemon should get less from his part and these walk on extras should get more for their part. Possibly. The strike isn’t about that though. At least not for the part of the actors.
It’s about the use of AI.
For actors, it’s about the use of AI likenesses. It’s increasingly becoming a problem. There was a story about the use of an AI generated Bruce Willis being used in commercials. Increasingly companies are adding clauses for AI Likeness use in actor contracts.
The issue here isn’t really an issue for Matt Daemon or Bruce Willis. They would be fine never working again ever (Bruce Willis actually can’t anymore due to declining health). It’s an issue for “nobody actors” like Ryan Rathbun, Jack Wang, and Ansa Woo. Because maybe they worked for a day, made a little money for some walk on background role. Maybe in a few years, the studio decides to make Oppenheimer 2: Nuclear Boogaloo, and they decide they need Female Student #70 to make another appearance, but hey, now they can save probably $500 and not bring Ansa Woo back on set again, they can just roll out the AI version.
In any movie.
Why bother with extras when you can just use AI and CGI to add them in. You don’t even need the detail of a leading actor like Matt Daemon or Bruce Willis, they just need to look good as an NPC sitting at a table 20 feet in the background slightly out of focus taking notes or drinking a coffee.
Then there is the writer’s side of things, which is just as bad, and also AI related. It wouldn’t be specifically ChatGPT, but the idea is that for a lot of these shows these days, studios could just, feed data to a LLM AI algorithm and then have it start spitting out episodes. This kind of just points out how sad the state of current TV is a bit, that an entire script could be written by spicy autocorrect, but the point remains, someone is out of the job. And in the case of some long lived shows, it’s still technically using effort put in by that person since it’ll be using old scripts.
And it’s definitely possible. There was a Twitch channel that was essentially just an endless loop of sloppy CGI 2 minutes bits based on Seinfeld. These were extremely repetitive in content and kind of shit, but the whole operation was clearly run on a very “fly by night” level and even a little bit of extra cash influx, like what a movie or television studio could do, would help it be “better”. As for the graphical part, well, Same concept, replace the shoddy CGI with an AI driven creation image. All for cheaper than the cost of hiring a bunch of real writers and actors.
Essentially, AI generated content would cause the entire media industry to completely stagnate even more, even faster, People joke about the world becoming Idiocracy, but this the kind of content that would feed that world. Simple idiot content for idiot people to just consume consume, please drink verification can!
The worst part of all this is, even if the writers and actors win this round, the studio execs won’t stop, and next time they won’t bat an eye at dropping these people. It’s all just so, frustrating, it’s part of why I stopped bothering with Stable diffusion after my initial tests and experiments. It’s just all so completely empty and soulless. It’s the end came of the focus group economy. Take the average and spit it out as “content” which just re-enters the system and churns back out until everything unique about art and media is just smoothed out and identical.

Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.










