Description: This full-colour reproduction of Aurora’s personal notebook also features all song lyrics from the album, as a beautifully presented cloth hardback with gold foiling. With original album artwork and stunning photography too, this book is a unique and immersive treasure trove for fans. ‘This is a little book I wrote, trying to figure out the soul of my album.’ – Aurora Aksnes
Liner Quotes: Aurora
Ketil Mosnes
Published: 2018 | Pages:93
My Rating: 5/5 A neat little book for those who are fans of Aurora, but its very light on the content and roughly half the pages are photos.
Description: This book documents the young singer’s 2016-17 travels from her rainy Bergen hometown to Los Angeles, and on to Australia, with exclusive interviews, personal recollections and intimate photographs. It offers a glimpse into–among other things–Aurora’s thoughts on success, her fans, world tours, and, of course, The Smurf Hits.Liner Quotes is a series designed to provide readers with informative and often humorous insight into the minds and lives of some of Norway’s most interesting musicians.
The Mysteries
Bill Watterson
Published: 2023 | Pages:72
My Rating: 4/5
Description: From Bill Watterson, bestselling creator of the beloved comic strip Calvin and Hobbes, and John Kascht, one of America’s most renowned caricaturists, comes a mysterious and beautifully illustrated fable about what lies beyond human understanding. In a fable for grown-ups by cartoonist Bill Watterson, a long-ago kingdom is afflicted with unexplainable calamities. Hoping to end the torment, the king dispatches his knights to discover the source of the mysterious events. Years later, a single battered knight returns.For the book’s illustrations, Watterson and caricaturist John Kascht worked together for several years in unusually close collaboration. Both artists abandoned their past ways of working, inventing images together that neither could anticipate—a mysterious process in its own right.
Taken by the Tetris Blocks: An Erotic Short Story (Digital Desires, #1)
Leonard Delaney
Published: 2014 | Pages:17
My Rating: 3/5
Description: Taken by the Tetris Blocks is a 4000 word short story featuring sexual situations involving blocks. It’s for super mature audiences only.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.
So, like many people within a pretty large range of my age, I was, and am, a huge fan of Calvin and Hobbes. I am sure Peanuts and Garfield would try to make the claim, and there is a good argument to be made for The Far Side, but Calvin and Hobbes may be the best newspaper comic there ever was. And that’s not really hyperbole. It perfectly road that line between, “appealing to younger folks” through Calvin’s adventures with his imaginary friend Hobbes (a stuffed cat who comes to life for Calvin), and still appealing to adults, by using clever metaphors to make statements on the real world.
It’s the kind of magic the Muppets have done for ages.
The strip only ran for ten years too, from 1985 to 1995. Bill Watterson, the creator, has also done something super interesting in that there is basically no Calvin and Hobbes merchandise. There was like, one school book and a couple of calendars, everything else is bootleg, including all those stupid “Calvin pissing on things” stickers. I assume he is doing okay for himself on the book sales, and I admire his refusal to cheapen his creation.
He also hasn’t done anything else since until now. He’s put out a new book, alongside another creator, John Kascht. The book has nothing to do with Calvin and Hobbes, but it’s worth mentioning the strip, because I am sure, like myself, a LOT of the interest in this book comes from people who loved Calvin and Hobbes. There are some videos and articles about the process, and the two apparently went back and forth a bit on how to present the visuals. It seems that Watterson did a lot of the painted backdrops, and Kascht did more of the physical foreground material. The images themselves are a combination, done using photos, that look a lot like elaborate illustrations. The story is quite simple in design and presentation but seems to mostly be the work of Watterson.
The book itself is essentially a “children’s book” in presentation, with a simple singular sentence on one page, and artwork on the opposite page. The artwork is very, very, bleak. I don’t mean it’s bad, I actually really like it, but good god it’s bleak. If you came into this expecting an upbeat comic book story, you’re not going to get it. The story is pretty bleak as well. It’s short, a rough count says, 35 pages long, maybe on average 10-15 words per page. This post is probably longer in total than the entire story. It follows something called The Mysteries, and their exit and subsequent return to the world. In Calvin and Hobbes fashion, the whole thing kind of feels like a metaphor for a few things. One being, how the society in the book basically exists in fear of the unknown, with no desire to really understand it or change. The later half takes quite a turn and seems to be a metaphor for the climate crisis.
Maybe I’m just projecting what I think it is, that’s kind of the beauty of writing sometimes, when done properly, the meaning is up to interpretation. This is also why I like a lot of the music I enjoy as well.
Also, I suppose I am kind of spoiling the story a bit but the story is pretty basic, and honestly, It’s not a book you buy for the story.
The book itself is quite nice. The size is a bit smaller than I expected, but it’s not too small or anything. The cover has this wonderfully textured cloth feel to it, and feels very sturdy, the pages themselves are nice heavy glossy paper. For the little content there is, the book definitely has been designed with a lot of care and consideration and desire to make a real quality product. It’s a “children’s book” story, with a very “adult presentation.” I suppose that’s the kind of work Watterson has always done, with the way Calvin and Hobbes was in its ability to be appreciated by younger and older folks.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.
I already have my Letterboxed watches set up to syndicate here, to this blog, for archival purposes mostly. When I log a movie in Letterboxed, a plug-in catches it from the RSS feed and makes a post. This is done using a plug-in called “RSS Importer” They aren’t the prettiest posts, I may look into adjusting the formatting with some CSS, but they are there. I really want to do the same for my Goodreads reading. Goodreads lists all have an RSS feed, so reason would have it that I could simply, put that feed into RSS Importer and have the same syndication happen.
For some reason, it throws out an error.
The feed shows as valid and even gives me a preview post, but for whatever reason, it won’t create the actual posts. This is probably actually ok, since the Goodreads RSS feed is weird and ugly. I’ll get more into that in a bit.
The Feed URL Is Here, at the bottom of each list.
I decided that I could simply, do it myself, with Python. One thing Python is excellent for is data retrieval and manipulation. I’m already doing something similar with my FreshRSS Syndication posts. I wanted to run through a bit of the process flow here though I used for creating this script. Partially because it might help people who are trying to learn programming and understand a bit more about how creating a program, at least a simple one, actually sort of works.
There were some basic maintenance tasks needing to be done. Firstly, I made sure I had a category on my WordPress site to accept the posts into. I had this already because I needed it trying to get RSS Importer to work. Secondly, I created a new project in PyCharm. Visual Studio Code works as well, any number of IDEs work, I just prefer PyCharm for Python. In my main.py file, I also added some commented-out bit at the header with URLs cut and pasted from Goodreads. I also verified these feeds actually worked with an RSS Reader.
For the actual code there are basically three steps to this process needed:
Retrieve the RSS feed
Process the RSS Feed
Post the processed data.
Part three here, is essentially already done. I can easily lift the code from my FreshRSS poster, replace the actual post data payload, and let it go. I can’t process data at all without data to process, so step one is to get the RSS data. I could probably work it out also from my FreshRSS script, but instead, I decided to just refresh my memory by searching for “Python Get RSS Feed”. Which brings up one of the two core points I want to make here in this post.
Programming is not about knowing all the code.
Programming is more often about knowing what process needs to be done, and knowing where and how to use the code needed. I don’t remember the exact libraries and syntax to get an RSS feed and feed it through Beautiful Soup. I know that I need to get an RSS feed, and I know I need Beautiful Soup.
My search returned this link, which I cribbed some code from, modifying the variables as needed. I basically skimmed through to just before “Outputting to a file”. I don’t need to output to a file, I can just do some print statements during debugging and then later it will all output to WordPress through a constructed string.
I did several runs along the way, finding that I needed to use lxml instead of xml in the features on the Beautiful Soup Call. I also opted to put the feed URL in a variable instead of directly in the code as the original post had it. It’s easy to swap out. I also did some testing by simply printing the output of “books” to make sure I was actually getting useful data, which I was.
At this point, my code looks something like this (not exactly but something like it:
import requests
from bs4 import BeautifulSoup
feedurl = "Goodreads URL HERE"
def goodreads_rss(feedurl):
article_list = [] try:
r = requests.get(feedurl)
soup = BeautifulSoup(r.content, features='lxml')
books = soup.findAll('item')
for a in books:
title = a.find('title').text
link = a.find('link').text
published = a.find('pubDate').text
book = {
'title': title,
'link': link,
'published': published
}
book_list.append(book)
return print(book_list)
print('Starting scraping')
goodreads_rss()
print('Finished scraping')
I was getting good data, and so Step 1 (above) was done. The real meat here is processing the data. I mentioned before, Goodreads gives a really ugly RSS feed. It has several tags for data in it, but they aren’t actually used for some reason. Here is a single sample of what a single book looks like:
<item>
<guid></guid>
<pubdate></pubdate>
<title></title>
<link/>
<book_id>5907</book_id>
<book_image_url></book_image_url>
<book_small_image_url></book_small_image_url>
<book_medium_image_url></book_medium_image_url>
<book_large_image_url></book_large_image_url>
<book_description>Written for J.R.R. Tolkien’s own children, The Hobbit met with instant critical acclaim when it was first published in 1937. Now recognized as a timeless classic, this introduction to the hobbit Bilbo Baggins, the wizard Gandalf, Gollum, and the spectacular world of Middle-earth recounts of the adventures of a reluctant hero, a powerful and dangerous ring, and the cruel dragon Smaug the Magnificent. The text in this 372-page paperback edition is based on that first published in Great Britain by Collins Modern Classics (1998), and includes a note on the text by Douglas A. Anderson (2001).]]></book_description>
<book id="5907">
<num_pages>366</num_pages>
</book>
<author_name>J.R.R. Tolkien</author_name>
<isbn></isbn>
<user_name>Josh</user_name>
<user_rating>4</user_rating>
<user_read_at></user_read_at>
<user_date_added></user_date_added>
<user_date_created></user_date_created>
<user_shelves>2008-reads</user_shelves>
<user_review></user_review>
<average_rating>4.28</average_rating>
<book_published>1937</book_published>
<description>
<img alt="The Hobbit (The Lord of the Rings, #0)" src="https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1546071216l/5907._SY75_.jpg"/><br/>
author: J.R.R. Tolkien<br/>
name: Josh<br/>
average rating: 4.28<br/>
book published: 1937<br/>
rating: 4<br/>
read at: <br/>
date added: 2011/02/22<br/>
shelves: 2008-reads<br/>
review: <br/><br/>
]]>
</description>
</item>
Half the data isn’t within the useful tags, instead, it’s just down below the image tag inside the Description. Not all of it though. It’s ugly and weird. The other thing that REALLY sticks out here, if you skim through it, there is NO “title” attribute. The boot title isn’t (quite) even in the feed. Instead, it just has a Book ID, which is a number that, presumably, relates to something on Goodreads.
In the above code, there is a line “for a in books”, which starts a loop and builds an array of book objects. This is where all the data I’ll need later will go, for each book. in a format similar to what is show “title = a.find(‘title’).text”. First I pulled out the easy ones that I might want when later constructing the actual post.
num_pages
book_description
author_name
user_rating
isbn (Not every book has one, but some do)
book_published
img
Lastly, I also pulled out the “description” and set to work parsing it out. It’s just a big string, and it’s regularly formatted across all books, so I split it on the br tags. This gave me a list with each line as an entry in the list. I counted out the index for each list element and then split them again on “: “, assigning the value at index [1] (the second value) to various variables.
The end result is an array of book objects with usable data that I can later build into a string that will be delivered to WordPress as a post. The code at this point looks like this:
import requests
from bs4 import BeautifulSoup
url = "GOODREADS URL"
book_list = []
def goodreads_rss(feed_url):
try:
r = requests.get(feed_url)
soup = BeautifulSoup(r.content, features='lxml')
books = soup.findAll('item')
for a in books:
print(a)
book_blob = a.find('description').text.split('<br/>')
book_data = book_blob[0].split('\n ')
author = a.find('author_name').text
isbn = a.find('isbn').text
desc = a.find('book_description').text
image = str(a.find('img'))
title = str(image).split('"')[1]
article = {
'author': author,
'isbn': isbn,
'desc': desc,
'title': title,
'image': image,
'published': book_data[4].split(": ")[1],
'my_rating': book_data[5].split(": ")[1],
'date_read': book_data[7].split(": ")[1],
'my_review': book_data[9].split(": ")[1],
# Uncomment for debugging
#'payload': book_data,
}
book_list.append(article)
return book_list
except Exception as e:
print('The scraping job failed. See exception: ')
print(e)
print('Starting scraping')
for_feed = goodreads_rss(url)
for each in for_feed:
print(each)
And a sample of the output looks something like this (3 books):
{'author': 'George Orwell', 'isbn': '', 'desc': ' When Animal Farm was first published, Stalinist Russia was seen as its target. Today it is devastatingly clear that wherever and whenever freedom is attacked, under whatever banner, the cutting clarity and savage comedy of George Orwell’s masterpiece have a meaning and message still ferociously fresh.]]>', 'title': 'Animal Farm', 'image': '<img alt="Animal Farm" src="https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1424037542l/7613._SY75_.jpg"/>', 'published': '1945', 'my_rating': '4', 'date_read': '2011/02/22', 'my_review': ''}
{'author': 'Philip Pullman', 'isbn': '0679879242', 'desc': "Can one small girl make a difference in such great and terrible endeavors? This is Lyra: a savage, a schemer, a liar, and as fierce and true a champion as Roger or Asriel could want--but what Lyra doesn't know is that to help one of them will be to betray the other.]]>", 'title': 'The Golden Compass (His Dark Materials, #1)', 'image': '<img alt="The Golden Compass (His Dark Materials, #1)" src="https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1505766203l/119322._SX50_.jpg"/>', 'published': '1995', 'my_rating': '4', 'date_read': '2011/02/22', 'my_review': ''}
{'author': 'J.R.R. Tolkien', 'isbn': '', 'desc': 'Written for J.R.R. Tolkien’s own children, The Hobbit met with instant critical acclaim when it was first published in 1937. Now recognized as a timeless classic, this introduction to the hobbit Bilbo Baggins, the wizard Gandalf, Gollum, and the spectacular world of Middle-earth recounts of the adventures of a reluctant hero, a powerful and dangerous ring, and the cruel dragon Smaug the Magnificent. The text in this 372-page paperback edition is based on that first published in Great Britain by Collins Modern Classics (1998), and includes a note on the text by Douglas A. Anderson (2001).]]>', 'title': 'The Hobbit (The Lord of the Rings, #0)', 'image': '<img alt="The Hobbit (The Lord of the Rings, #0)" src="https://i.gr-assets.com/images/S/compressed.photo.goodreads.com/books/1546071216l/5907._SY75_.jpg"/>', 'published': '1937', 'my_rating': '4', 'date_read': '2011/02/22', 'my_review': ''}
I still would like to get the Title, which isn’t an entry, but, each Image, uses the Book Title as its alt text. I can use the previously pulled-out “image” string to get this. The image result is a complete HTML Image tag and link. It’s regularly structured, so I can split it, then take the second entry (the title) and assign it to a variable. I should not have to worry about titles with quotes being an issue, since the way Goodreads is sending the payload, these quotes should already be removed or dealt with in some way, or the image tag itself wouldn’t work.
title = str(image).split('"')[1]
I’m not going to go super deep into the formatting process, for conciseness, but it’s not really that hard and the code will appear in my final code chunk. Basically, I want the entries to look like little cards, with a thumbnail image, and most of the data pulled into my array formatted out. I’ll mock up something using basic HTML code independently, then use that code to build the structure of my post string. It will look something like this when finished, with the variables stuck in place in the relevant points, so the code will loop through, and insert all the values:
I don’t use all of the classes added, but I did add custom classes to everything, I don’t want to have to go back and modify my code later if I want to add more formatting. I did make a bit of simple CSS that can be added to the WordPress custom CSS (or any CSS actually, if you just wanted to stick this in a webpage) to make some simple cards. They should center in whatever container they get stuck inside, in my case, it’s the WordPress column.
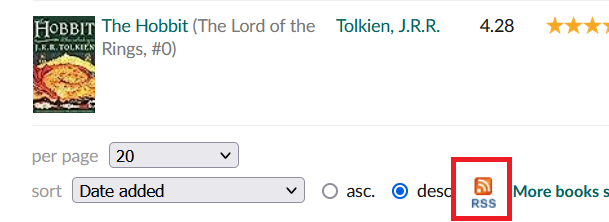
The end result looks something like this. Unfortunately, the images in the feed are tiny, but that’s ok, it doesn’t need to be huge.
Something I noticed along the way, I had initially been using the “all books” RSS feed, which meant it was giving all books on my profile, not JUST read books. I switched the RSS feed to “read” and things still worked, but “read” only returns a maximum of 200 books. Fortunately, I use shelves based on year for my books, so I can go through each shelf and pull out ALL the books I have read over the years.
Which leads me to a bit of a split in the process.
At some point, I’ll want to run this code, on a schedule somewhere, and have it check for newly read books (probably based on date), and post those as they are read.
But I also want to pull and post ALL the old reads, by date. These two paths will MOSTLY use the same code. For the new books, I’ll attach it to the “read” list, have it check the feed, then compare the date added in the latest entry, entry [0], to the current date. If it’s new, say, within 24 hours, it’ll post the book as a new post.
Change of plans. Rather than make individual posts, I’m going to just generate a pile of HTML code, and make backdated posts for each previous year. Much simpler and cleaner. I can then run the code once a year and make a new post on December 31st. Goodreads already serves the basic purpose of “book tracking”, I mostly just want an archive version. It’s also cleaner looking in the blog and means I don’t need to run the script all the time or have it even make the posts itself.
For the archive, I’ll pull all entries for each of my yearly shelves, then make a post for all of them, replacing the “published date” on each with the “date added” date. Because I want the entries on my Blog to match the (approximate) finished date.
I think, we’ll see.
I’ve decided to just strike out these changes of plans. After making the post, I noticed the date added, is not the date read. I know the yearly shelves are accurate, but the date added is when I added it, probably from some other notes at a later date. Unfortunately, the RSS feed doesn’t have any sort of entry for “Date Read” even though it’s a field you can set as a user, so I just removed it. It’s probably for the best, Goodreads only allows one “Date Read,” so any books I’ve read twice, will not be accurate anyway.
This whole new plan of yearly digests also means in the end I can skip step 3 above. I’m not making the script make the posts, I can cut and paste and make them manually. This lets me double-check things. One little bit I found, there was an artifact in the description of some brackets. I just added a string slice to chop it off.
I guess it’s a good idea to at some point mention the second of the two points I wanted to make here, about reusing code. Programming is all about reusing code. Your own code, someone else’s code, it doesn’t matter, code is code. There are only so many ways to do the same thing in code, they are all going to look generically the same. I picked out bits from that linked article and made them work for what I was doing, I’ll pick bits from my FreshRSS poster code, and clean it up as needed to work here. I’ll reuse 90% of the code here, to make two nearly identical scripts, one to run on a schedule, and one to be run several times manually. This also feeds back into point one, knowing what code you need and how to use it. Find the code you need, massage it together into one new block of code, and debug out the kinks. Wash, rinse, repeat.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.
Just for establishment up front here, I am a big fan of the musician Aurora. If we’re measuring by Last.fm scrobbles, which I like to do, she has very rapidly become my top scrobbled artist, of all time. But a pretty large margin. I saw this book posted by someone in a fan group on Facebook and it seemed like a pretty interesting, and probably less known bit of Aurora memorabilia, almost no one in the group was aware of it as far as I could tell. It’s also tricky to find, I had to order it from a bookseller in Norway. The book itself was pretty inexpensive, the shipping pretty much tripled the price.
Which is kind of the main negative, unless you happen to be somewhere that you can just buy this little book, it’s very very light on content. I don’t regret the purchase, but I was surprised that the book is much small is size than expected and roughly half of it’s few pages are photographs. The book itself is about the size of a manga book or a DVD case.
The book itself was written by a person who was able to travel around with Aurora’s crew briefly, though they aren’t really officially part of the grew. It contains a half dozen or so short interview excerpts and a bunch of photos. I will say, most of the photos are ones that I had never seen before, which was nice. Probably a side effect of the book being a bit of a lesser known artifact. There is a nice mix of behind the scenes photos and a few actual concert photos. They are a bit small though, given the size of the book, but it’s not like they are going to be torn out and displayed or something either. The photos themselves are clumped together in section, as opposed to mixed in with the text that relates to them, which feels like a side effect of using slightly nicer paper for the photo pages.
The real meat is the short interview parts. These are excepts from Aurora’s touring during 2016-2017. The writer also at least seems to be on pretty good terms with Aurora and it helps to give some fresh direction to the questions asked. It’s also worth noting for anyone not familiar with Aurora, she is, truly, absolutely, a unique and interesting person. There are plenty of in person interviews around on Youtube for examples of her all around oddness. She genuinely works to see the good in everything and to be good to everyone. The interview is dotted with lots of interesting takes on various things, I won’t go into detail on it all because well, that’s kind of the point of reading the book, but it’s definitely amusing at times, while sad at others.
I guess a good way to summarize it is to say she wears her emotions and herself not just on her sleeve, but on her entire self. If you’re a fan of Aurora, it’s certainly worth a read, and it’s a neat little book. I certainly enjoyed it, despite how short it is.
On another side note, the descriptions on this book suggest that “Linear Quotes” is a series, but as near as I can tell, this is the only one. Which is a bit disappointing because I would actually like to read more books like this.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.
Mastering The Game: What Video Games Can Teach Us About Success In Life
Jon Harrison
Published: 2015 | Pages:294
My Rating: 3/5
Description: Mastering The Game: What Video Games Can Teach Us About Success In Life takes a look at how the same habits and principles that lead to success when playing video games can be applied to personal and business success. Principles are ideas that are truly timeless, and remain true independent of context, culture or time period. So what are the principles embedded in the most popular video games? Surprisingly, the list strongly resembles the most in demand traits for the workplace. • Adaptability & Managing Change • Personal Accountability • Innovation • Communication & Listening • Teambuilding & Collaboration • Knowledge Sharing • Persistence & Grit Mastering The Game provides analogies, examples, and lessons for connecting the dots between how gamers play and how successful professionals work. Are you ready to take your career to the next level?
Scott Pilgrim, Volume 3: Scott Pilgrim & The Infinite Sadness
Bryan Lee O’Malley
Published: 2006 | Pages:192
My Rating: 4/5
Description:
Scott Pilgrim, Volume 4: Scott Pilgrim Gets It Together
Bryan Lee O’Malley
Published: 2007 | Pages:216
My Rating: 4/5
Description:
Scott Pilgrim, Volume 5: Scott Pilgrim vs. the Universe
Bryan Lee O’Malley
Published: 2009 | Pages:184
My Rating: 4/5
Description:
Scott Pilgrim, Volume 6: Scott Pilgrim’s Finest Hour
Bryan Lee O’Malley
Published: 2010 | Pages:245
My Rating: 5/5
Description:
Scott Pilgrim’s Precious Little Life (Scott Pilgrim, #1)
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.