More often that it feels like it should, something in technology breaks or fails. I find that this can be frustrating, but often ultimately good, especially for learning something new, and forcing myself to clean up something I’ve been meaning to clean up. I have a Raspberry Pi I’ve been using for a while for several things as a little web server. It’s been running probably for years, but something gave out on it. I’m not entirely sure it’s the SD card or the Pi itself honestly, because I’ve been having a bit of trouble trying to recover through both. It’s sort of pushed me to try a different approach a bit.
But first I needed a new SD card. I have quite a few, most are “in use”. I say “in use” because many are less in use and more, underused. This has resulted in doing a bit of rebuild on some other projects to make better use of my Micro SD cards. The starting point was a 8 GB card with just a basic Raspbian set up on it.
So, for starters, I found that the one I have in my recently set up music station Raspberry Pi is a whopping 128gb. Contrary to what one might thing, I don’t need a 128gb card in my music station, the music is stored on the NAS over the network. It also has some old residual projects on it that should really be cleaned out.
So stuck the 8GB card in that device and did the minor set up needed for the music station. Specifically, configure VLC for Remote Control over the network, then add the network share. Once I plugged it back into my little mixer and verified I could remote play music, I moved on.
This ended up being an unrelated side project though, because I had been planning on getting a large, speedy, Micro SD card to stick in my Retroid Pocket. So I stuck that 128GB card in, the Retroid and formatted it. This freed up a smaller, 32GB card.
I also have a 64GB that is basically not being used in my PiGrrl Project I decided to recover back for use. The project was fun, but the Retroid does the same thing 1000x better. So now it’s mostly just a display piece on a shelf. Literally an overpriced paperweight. I don’t want to lose the PiGrrl configuration though, because it’s been programmed up to work with the small display and IO Control Inputs. So I imaged that card off.
In the end though, I didn’t end up needing those Micro SD cards though, I opted for an alternative option to replace the Pi, with Docker on my secondary PC. I’ve been meaning to better learn Docker, though I still find it to be a weird and obtuse bit of software. There are a handful of things I care about restoring that I used the Pi for.
- Youtube DL – There seem to be quite a few nice Web Interfaces for this that will work much better than my old custom system.
- WordPress Blog Archives – I have exported data files from this but I would like to have it as a WordPress Instance again
- FreshRSS – My RSS Reader. I already miss my daily news feeds.
YoutubeDL was simple, they provided a nice basic command sequence to get things working.
The others were a bit trickier. Because the old set up died unexpectedly, The data isn’t easily exported for import, which means digging out and recovering off of the raw database files. This isn’t the first time this has happened, but its a lot bigger pain, which isn’t helped by not being entirely confident in how to manipulate Docker.
I still have not gotten the WordPress archive working actually. I was getting “Connection Reset” errors and now I am getting “Cannot establish Database connection” issues. It may be for nothing after the troubles I have had dealing with recovering FreshRSS.
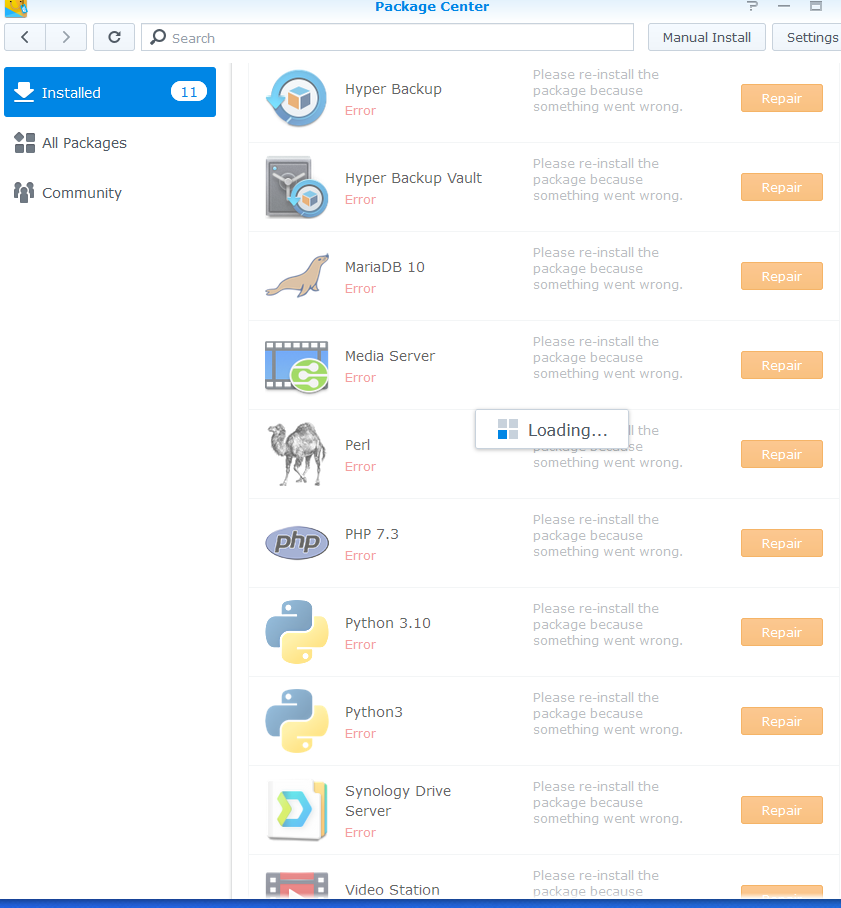
I have gotten FreshRSS fixed though. Getting it running in Docker was easy peasy. Getting my data back, was… considerably less so. It’s been plaguing me now when I try to fix it for a few weeks now, but I have a solution. It’s not the BEST solution, but it’s… a solution. So, the core thing I needed were the feeds themselves. Lesson learned I suppose, but I’m going to find a way to automate a regular dump of the feeds once everything is reloaded. I don’t need or care about favorited articles or the articles contents. These were stored in a MySQL database. MySQL, specifically seems to be what was corrupted and crashed out on the old Pi/Instance because I get a failed message on boot and i can’t get it to reinstall or load anymore.
Well, more, I am pretty sure the root cause is the SD card died, but it affected the DB files.
My struggle now, is recovering data from these raw files. I’ve actually done this before on a surver crash years ago, but this round has lead to many many hurdles. One, 90% of the results looking up how to do it are littered with unhelpful replies about using a proper SQL dump instead. If I could open MySQL, I sure as hell would so that. Another issue seems to be that the SQL server running on the Pi was woefully out of date, so there have been file compatibility problems.
There is also the issue that the data may just flat out BE CORRUPTED.
So I’ve spun up and tried to manually move the data to probably a dozen instances of MySQL and MariaDB of various versions, on Pis, in Docker, on WSL, in a Linux install. Nothing, and I mean NOTHING has worked.
I did get the raw data pulled out though.
So I’ve been brute forcing a fix. Opening the .ibd file in a text editor gives a really ugly chuck of funny characters. But, strewn throughout this, is a bunch of URLs for feeds and websites and well, mostly that. i did an open “Replace” in Notepad++ that stripped out a lot of the characters. Then I opened up Pycharm, I did a find and replace with blanks on a ton of other ugly characters. Then I write up this wuick and dirty Python Script:
# Control F in Notepad++, replace, extended mode "\x00"
# Replace " " with " "
# replace "https:" with " https:"
# rename to fresh.txt
## Debug and skip asking each time
file = "fresh.txt"
## Open and read the Log File supploed
with open(file, encoding="UTF-8") as logfile:
log = logfile.read()
datasplit = log.split(" ")
links = []
for each in datasplit:
if "http" in each:
links.append(each)
with open("output.txt", mode="w", encoding="UTF-8") as writefile:
for i in links:
writefile.write(i+"\n")
Which splits everything up into an array, and skims through the array for anything with “http” in it, to pull out anything that is a URL. This has left me with a text file that is full of duplicates and has regular URLs next to Feed URLS, though not in EVERY case because that would be too damn easy. I could probably add a bunch of conditionals to the script to sort out anything with the word “feed” “rss”, “atom” or “xml” and get a lot of the cruft removed, but Fresh RSS does not seem to have a way to bulk import a text list, so I still get to manually cut and paste each URL in and resort everything into categories.
It’s tedious, but it’s mindless, and it will get done.
Afterwards I will need to reset up my WordPress Autoposter script for those little news digests I’ve been sharing that no one cares about.
Slight update, I added some filtering ans sorting to the code:
# Control F in Notepad++, replace, extended mode "\x00"
# Replace " " with " "
# replace "https:" with " https:"
# rename to fresh.txt
## Debug and skip asking each time
file = "fresh.txt"
## Open and read the Log File supploed
with open(file, encoding="UTF-8") as logfile:
log = logfile.read()
datasplit = log.split(" ")
links = []
for each in datasplit:
if "http" in each:
if "feed" in each or "rss" in each or "default" in each or "atom" in each or "xml" in each:
if each not in links:
links.append(each[each.find("http"):])
links.sort()
with open("output.txt", mode="w", encoding="UTF-8") as writefile:
for i in links:
writefile.write(i+"\n")
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.