100 Days of Python, Projects 58-65 #100DaysofCode
Judging by the comments on the lessons, The lessons are getting harder, though frankly, I am finding they are a bit easier. I feel like my experience with Web Design is a lot of this. I also have been looking a bit into how to properly host some of these apps to share here, on my Code Projects Page. I believe I could set them up to run on a production Flask environment, with different ports, then just map sub directories n the domain to different ports.
But I am doing my best not to get distracted. Yes, I have been building a few smaller projects here and there lately, but I don’t want to get TOO distracted.
Day 58 – Bootstrap Overview
Not a lot of really say here, like the Web Foundational section, this was a chunk of the Web Dev course offered by the same Instructor. I may look into picking it up if it’s on sale for cheap, since at this point I’ve done like half of it. My next plan for a major learning push is going to be Javascript. I really need to get familiar with Javascript for some work projects.
The project was essentially using different Bootstrap bits to format a silly Tinder knockoff website, a site for Dogs called Tindog. Bootstrap is definitely useful, but I generally try to avoid it because it makes things look very samey. I suppose familiarity in design is useful at times though.
Day 59 and 59 – Blog Capstone Project Part 2
The last part of the Intermediate+ section was the bones of a Clean Blog running in Python Flask. These two days expanded on the Blog concept a bit, and a few later lessons bring it back around again. I am almost interested in trying to use the blog once finished, except that I already have plenty of proper outlets for Blogging. Wordpress works fine.
The core concept was using Bootstrap to format the blog up nicely, as well as setting it up to reuse Header and Footer files. It’s a common method for webdesign, and it’s one I have been using since Geocities when I discovered something called SHTML which would let me write Blog Texts in HTML, then encapsulate them into a common top and bottom.
Day 61 – Flask Forms
An intro to easier to use Flask based forms and libraries. The project itself was to construct a simple log in page, which lead to a Rick Roll when unlocked. I could see this piece being useful later to add in on the more complete Blog project.
Which brings to a bit of an aside topic. A lot fo these projects feel disconnected, but really, they are demonstrating a proper way of handling larger Code Projects.
Break it into parts.
We built a simple blog page that pulled posts from a CSV file.
We formatted that blog page.
We created a log in form, that could easily be slipped into a blog page.
Later lessons work with more dynamic forms and data and SQL Lite databases.
As the pieces get laid out, the end goal becomes more and more clear. My prediction is that the later Blog Capstone project will amount to, “Take everything from the last ten weapons and mash it into a functioning Blog app.
Day 62 – Coffee Shop Wifi Tracker
Like I said, building on the last. For this lesson, we built a little table that would list Coffee Shops in pretty Bootstrap table with ratings for Coffee Quality, Wifi Quality, and Power Outlet availability. Instead of just a form that takes an input and verifies it’s good, it actually inserts new data into the CSV that holds all the coffee shops.
Day 63 – Book Collection App
I may revisit this one later to build an app for my other collections. And to make it more robust. The core though is once again, building on the Coffee App, essentially. Instead of just a tracked list with an Add Form, we added persistence by learning about SQL Lite databases. So the data persists even if the server is shut down.
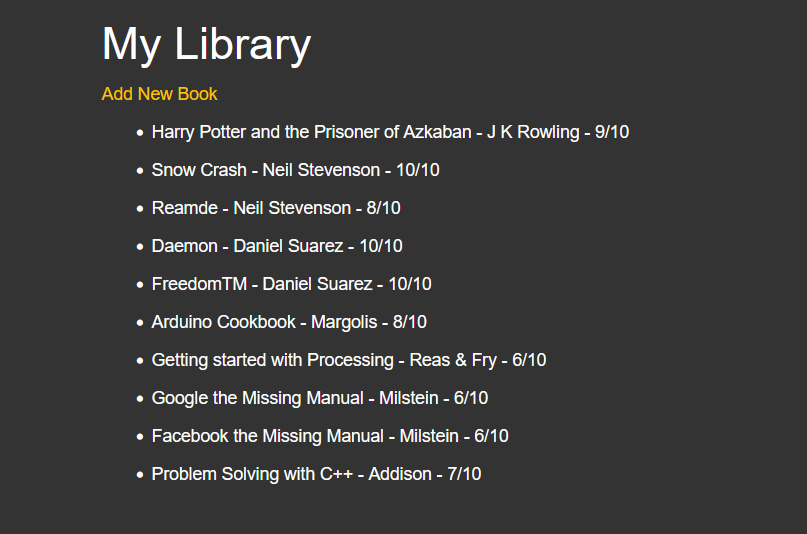
I took a few extra non required steps on this app and reused the Coffee Shop code to make this app look much nicer. The core app and instructions just had a very basic page with an unordered list. I turned it into a table with a bit more formatting and color.
Day 64 – Top Ten Movies App
This whole project was essentially the same as the Book Collection App, except it was intnded from the start to look prettier. The main difference is that the add process had a few extra steps to pull from the API of The Movie DataBase website to get data about each film, and have the user select from a list of results. In the instructions for the class, the idea was to make multiple API calls for the list, then specific movie data, but I had already worked ahead on the project and instead it pulls the data, the user selects the movie, then it’s just done. It was a bit complicated to get the data to pass around between pages since it was a dictionary and not just a single variable, but I got it working using Global variables.
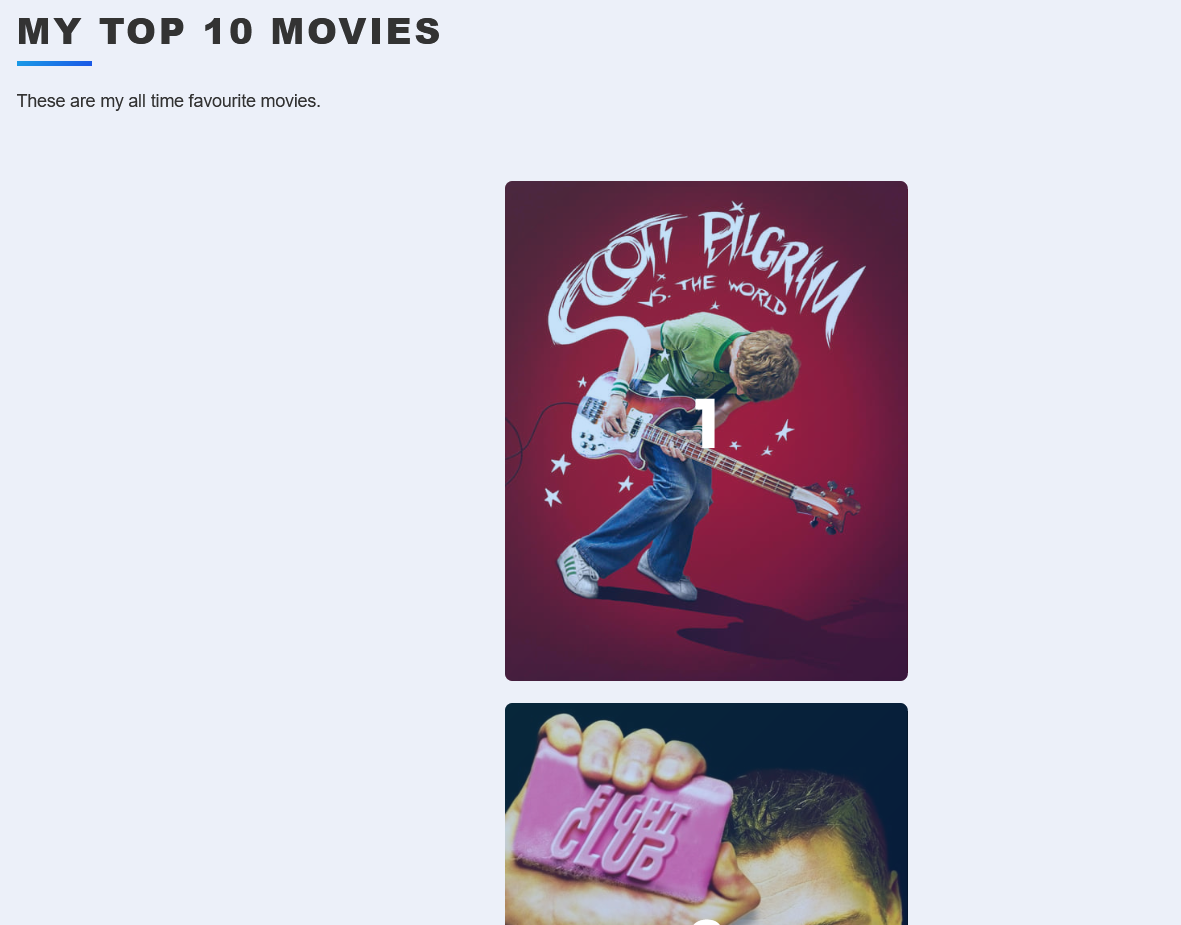
I mostly try to avoid Global variables, but it felt like this was a good use case and made sense to use given the way Flask works.
I am thinking I may integrate the log in app created previously with this website and use it to test out mapping some of these projects to a domain to make it a for real, live website. Also, you can’t tell it in the snapshot but the posters do this cool flip over effect when you mouse over them to show more information. Not really a Python thing, but it’s still a neat effect.
Day 65 – Web Design Principles
No project for this day, it’s another slice of the Web Developer course from the same instructor. I’m definitely going to keep an eye out for a deep discount, especially with Black Friday coming, since I’ve basically completed half of that course now.
I was hoping to fit all of this more advanced Flask based projects into one page but it feels like this post is getting pretty long so I’m going to go ahead and break it up here.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.