Things are continuing to be interesting and useful here with the introduction of Beautiful Soup, a tool used to parse unstructured data into usable structured data. Well, more or less that’s what it does. Useful for parsing through Scraped Web Page data that does not have it’s own API available.
As normal, everything is on GitHub.
Day 45 – Must Watch Movies List and Hacker News Headline Scraper
As an introduction to using the tool, Beautiful Soup, we had two simple projects. The training project actually feels more useful than the official project of the day, though I also remixed the training project a bit.
The “Project of the Day” was to scrape the Empire Magazine top 100 Must watch movies and output them to a text file. I am pretty sure this list does not change regularly and this it’s sort of a “one and done” run.
The trainer project was more interesting, because it scraped the news headlines from Hacker News, a Reddit-like site centered around coding and technology that is absolutely bare bones in it’s interface. The course notes were just to get the “top headline of the day”, but I modified mine to give a list of all headlines and links. I will probably combine this with the previously covered email tools to get a digest of stories each day emailed to myself.
Day 46 – Spotify Musical Time Machine
This one combines the web scraping with the use of APIs which was covered previously. Specifically the Spotify API. The object is to get the user to input a date, then scrape the Billboard Top 100 for that date and create a Spotify Playlist based on the return.
This one was actually tricky and, as I often do, I added a bit to keep it robust. Firstly I created a function to verify if the entered date was, in fact, a valid date. Knowing my luck, there is a function that does this in Date Time, but writing it up was fun. It could be better though, it only verifies if the day is between 1 and 31, for example. Something I may clean up later I think.
The real tricky part was dealing with the scraping. Billboard’s tables are not very clean and not really scrap-able. I had come up with a way to get all the Song Titles, but the resulting list was full of garbage data. I set about collecting the garbage data out by filtering the results list through a second list of keywords, but I noticed someone int he comments had found a simple solution of using Beautiful Soup to search for “li” (list items) with an “h3” (heading 3), which easily returned the proper list.
So I tried the same for the artists, filter by “li” then by “span” which …. returned 900 items. So I added another filter on the class used by the “span” containing the artist, which did not help at all. Fortunetely, I already had solved this problem before while working on the Song List. I created a list of keywords and phrases to filter, then ran my result across it, eventually I was able to output 100 sets of “Song Title – Artist name”.
The real tricky part was using the Spotify API. Ohhhh boy what a mess. There seems to be several ways to authenticate, and they don’t work together, and the API Documentation for Spotify and SpotiPy are neither amazing. It took a lot of digging on searches and testing to get the ball rolling, then some more help with code around the web. But hey, that’s part of what coding is, “Making it work”.
The first issue was getting logged in, which meant using OATH and getting a special auth token, which Spotipy would use to authenticate with.
The second issue, once that was working, was to create the playlist, which didn’t end up being too hard, just one line of Spotipy code and output the goof ID key to a variable from the response. Still, I deleted so many “Test List” playlists from my account.
So, the real tricky part, was that Spotify doesn’t work super great if you just search with “artist” and “track”. Instead you get the ID of the artist, then search within that artist for the track, which works much more smoothly. Why? To add tracks to a playlist, you add them by Spotify IDs. Thankfully, I could throw a whole List of them up at once.
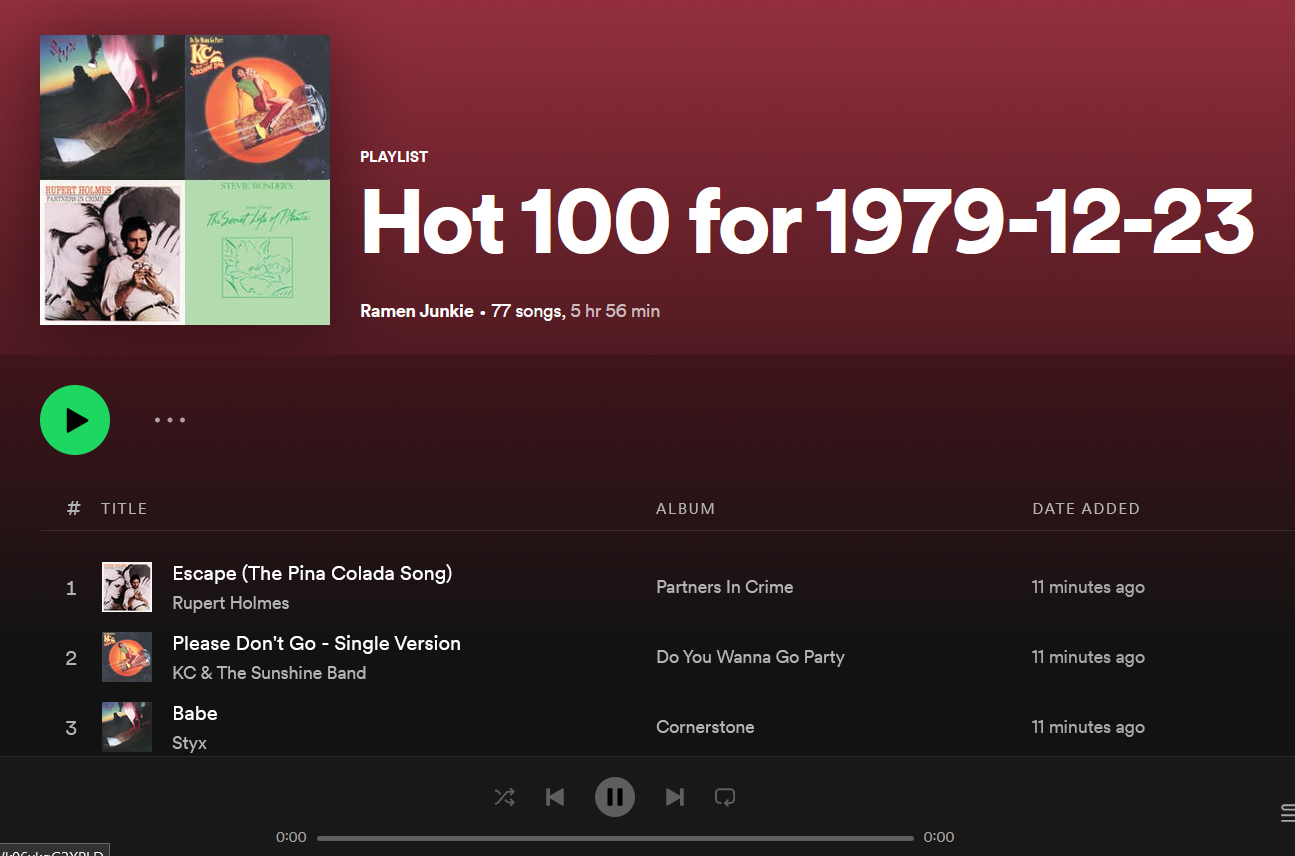
The end result works pretty flawlessly though, which is cool. Though It also shows some of the holes in the Spotify Catalogue as you get into older tracks. My playlist for my birthday, in 1979, is missing 23 tracks out of 100.
Also, I may look into if there is an API for Amazon Music int he future, since that is what I use instead of Spotify, sometimes.
Day 47 – Amazon Price Tracker
Ok, this one will actually be useful to me in the long run. Like actually useful. I already use sites like Camel Camel Camel but running my own tracker would be even better. Especially because one of my other primary hobbies is collecting Plastic Crack (toys). Geting deals on things is definitely useful, especially given how expensive things are these days.
Also, I have not found a good way to monitor for sales/price drops on eBooks, which is another advantage to straight scraping web pages.
So I even added to this one a bit. Instead of looking for one item, it reads links and desired proces from a text file. Now, if you look at the code, it probably could be cleaned up with a better import, treating it as a CSV instead of raw text, but I wanted to keep things as simple as possible for anyone who might run this script to monitor proces. It’s just “LINK,PRICE”. Easy, simple.
Day 48 – Selenium Chrome Driver
The Day 48 Lesson was an intro to the Selenium Chrome Driver software. This is a bridge tool, that I imagine can connect to many languages, but in this case we used Python, that can open it’s own dummy web browser window, then read and interact with it.
So the first bit was just some general example, followed by actually using it to pull the events list from Python.org and dump them into a dictionary. I could actually see this being useful for various sites because so few sites have easy to find calendar links for events. I’m sure there is some way to add calendar events to a calendar with Python. Just one for the “future projects” list.
Afterwards we learned about some interaction with Selenium, filling in forms and clicking links to navigate Wikipedia.
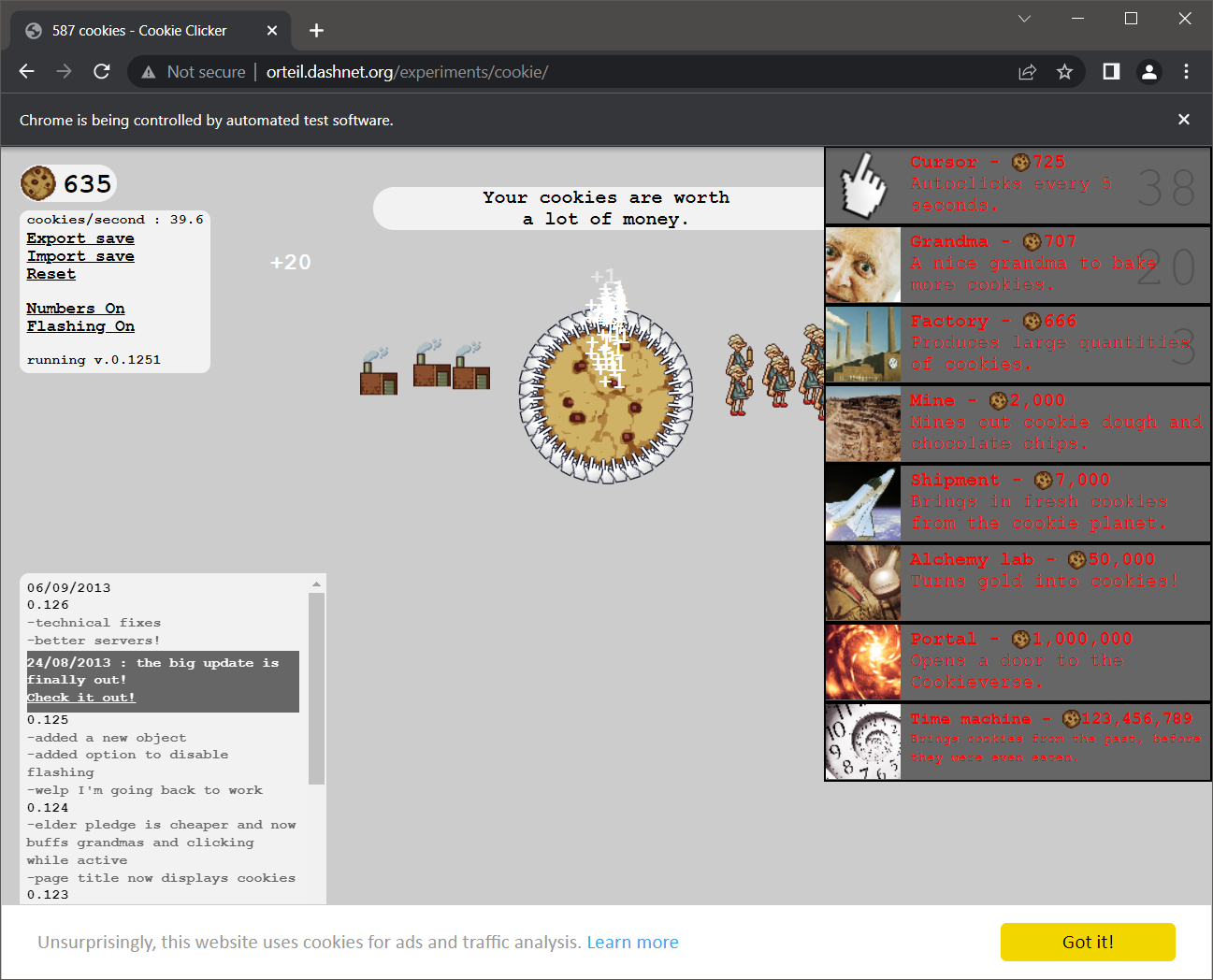
Finally the day’s project was to automate playing a Cookie Clicker game. These “Clicker” games are pretty popular with some folks and basically amount to clicking an object as quickly as possible. The game includes some upgrades and the assignment itself was pretty open on how to handle upgrades. There was a sort of side challenge to see who would get the highest “Cookies Per Second”. I set mine up to scan the prices each round and if something could be bought, buy it. This got me up to about 50 CPS after 5 minutes. It could be better. I may go back and adjust it to stop buying lower levels once a higher level can be bought, which I think might be a better method. Why buy Grandmas when you could buy Factories.
Day 49 – Linked in Job Applier
So, I completely overhauled this one, but kept it in the spirit of things, because the point is more to practice using Selenium in more complex ways. The original objective, was to make a bot that would open LinkedIn, sign in to your account, go to the Jobs Page, search for “Python Developer”, find jobs with “Easy Apply” and click through the Apply Process.
I am not in the market for a job, so applying for random jobs seems like a dumb idea. I also use 2-Factor on my LinkedIn account, so logging in automatically would be quite impossible. It was suggested to make a “Fake Account” to get around this but that seems a bit rude. It also suggested simply following companies instead of applying, but I’d rather not clutter up my feed with weird false signals.
So instead…
My Bot will open LinkedIn, go to to the Jobs Page for each term in an array of job terms individually, (for the test I used “Python Developer” and “Java Developer”). Then it takes those results, strips out the Company Name and URL to the Job Opening, and compiles them into an email digest that it sends out.
One issue I did have is that LinkedIn apparently uses different CSS for Chrome versus Firefox, because I was just NOT getting the results back for the links to each job, and it turns out the link bit has a different Class in Chrome, which Selenium was using, than Firefox, which I was using to inspect code (and use as my browser).
Anyway, it works in the spirit of what was trying to be accomplished, without actually passing any real personal data along.
Day 50 – Tinder Auto Swiper
So, I am really not in the market to use Tinder at all. I was going to just skip this one.
Then I decided, “You know what, I can make a fake profile with a “https://www.thispersondoesnotexist.com/” profile.
But then it seems dumb to get people to match with a bot.
No wait, I can set up the bot to Reject everyone, swipe, whatever direction “reject” is. No matches!
Oh, it needs a log in via Google, Facebook, or Phone Number. Never mind.
No wait, I have some old Facebook Profiles for a couple of my cats, I will just use one of those to log in with!
Oh, it still wants a phone number.
So anyway, I decided even trying to fake it was not worth the trouble. But hey, Halfway there!
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.