Whew, I didn’t really think I’d get to 9 parts in this series, and I am only around 2/3rds of the way through even. I actually may change up the format later with the last 20 projects that are listed as “Professional”. Maybe one post each.
The bulk of this round is wrapping up the Flask projects and building a simple blog that runs on Python. It’s been fun. I’ve been a bit busier than normal slow my pace has slowed, but that’s ok too. Day 66 in particular felt like it took longer than it really should have, given how little it felt like it was doing.
Day 66 – Build RESTful APIs
Kind of a different sort of project. It’s building something, but not really anything, with any sort of interface. All of the interaction is done through Postman (or the URL if one wants), and the responses are all JSON of some sort.
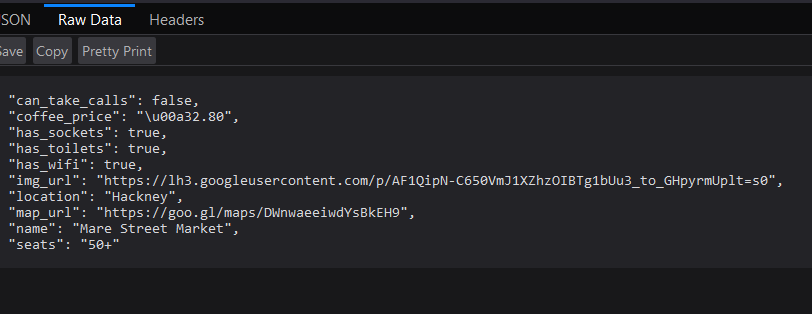
We built 6 API interfaces to work with a database of Coffee shops.
- One returned all of the shops.
- One returned all of them in a particular city.
- One returned a specific shop only.
- One updated the price of coffee.
- One added a new Coffee Shop.
- One deleted a Coffee Shop.
Including built in error handling for if a Coffee Shop didn’t exist etc. It all feels like it could be useful later in the Blog Project. Not too useful on it’s own accord.
Day 67 – Blog Capstone Project Part 3
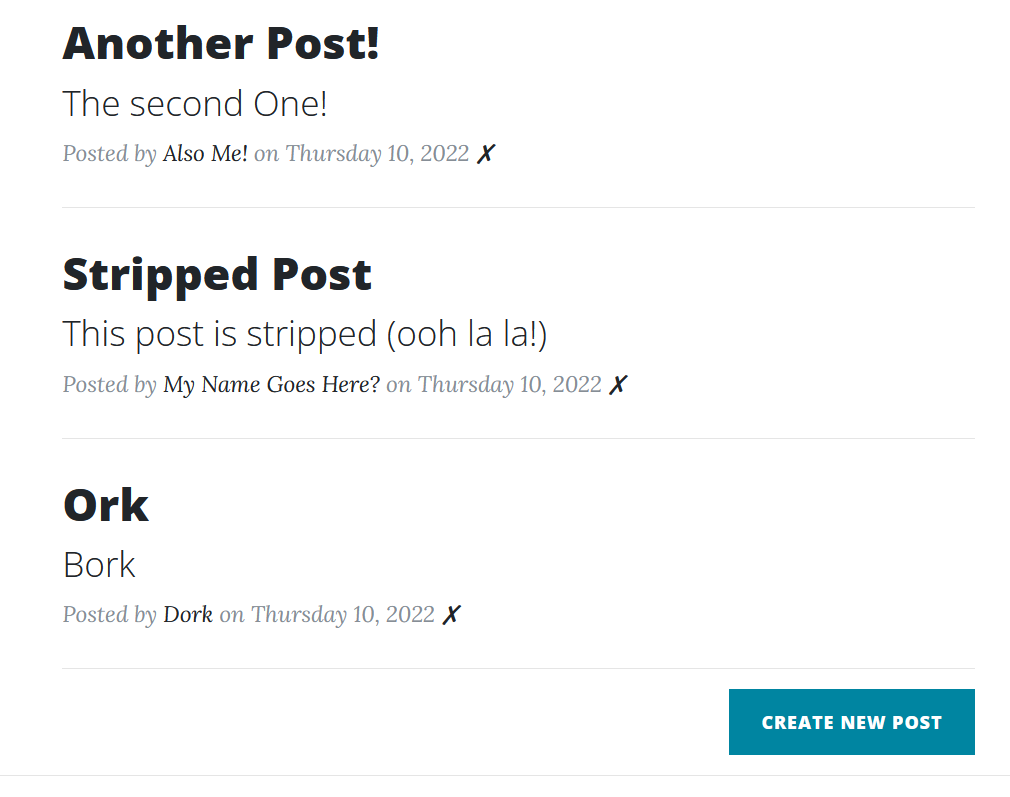
Back to the Blog Project, and after this round it’s a LOT more Blog Like, though incredibly insecure. The Security Part looks to be the subject of the next couple of lessons though, so it’s all good. We basically started with the last Blog Project from Day 59, and added the ability to add, edit, and delete posts. Also with a Database back end.
One tricky moment here. The idea was to use the same form page for New Post and Edit Post. Originally I had nested these together, and had some if/else cases to check if it was Editing or Adding, and kind of got stuck on how to handle the date, since the date doesn’t get changed on updates.
But then I had a bit of an epiphany moment, the kind you get often with coding, where you band against a problem, convinced it’s the way to solve things, only to realize there is an obvious, easy method.
I split them up. No more if/else, and no more worrying about what the DB is doing at the end. Because two separate @app.route and related functions, can route to the same HTML template (the Edit Form). The only thing needed was to pass a header variable along to change the title.
It was a total “Duuuuuuh” moment.
Anyway, no security though, because there are no users or security keys and anyone can just come in and post anything and delete anything and it would be total chaos as an actual production Blog platform.
Day 68 – Authentication with Flask
Oops, I spoiled what this topic was going to be in the last project write up. This whole section is working with Authentication using a Database for persistence. It’s a simple website, a home page, a user creation page, a log in page, and a secrets page. Users can create an account, and once registered, they can access the Secrets page and download a PDF.
Part of this exercise is also restricting access for not logged in users and another part is proper security and handling passwords with hashing and salting.
Of all of the projects so far, I feel like this may be one of the most important ones, despite it’s basic simplicity. I’ve been planning to work out the best way to share some of the projects built so far, and using Flask was a good “first step”, but being security conscious, I would rather not throw a bunch of web based Flask pages up with no restrictions on access. Like last session, there was the Library App or the Top Ten Movies page. Sure, I could put them up on the web-server, map some sub domain to them, but anyone can edit them, without proper, persistent security and restricted access.
Now, I can make that happen. Plus, with the modulator of routing and such, I can easily slip them into parts of the overall Blog Project, in time.
Day 69 – Blog Capstone Project Part 4
And here it is, the culmination of the Python based Flask Blog. It’s neat. I like it, well, I like the basic functionality of it. The layout is a bit plain but that’s fixed. I doubt it ever replaces WordPress, I love WordPress, but I could definitely see uses for this finished product. I may actually modify it to work as a sort of “Twitter Replacement” since Twitter is currently burning down. Using what I have learned, I could easily set this up to take a post, then “Syndicate” it out via API calls to Twitter, Facebook, Mastodon, or anywhere. While keeping my own archive of posts.
My current, next up To Do Items:
- Create RSS Feed Page
- Create Admin Page
- Enable/Disable Comments for Posts
- Allow Admin to delete Comments
- Allow Users to delete their own comments
- Add Mailer.class and add email notifications
- Add Pagination to Home Page
- Add Tags and Category Options to Posts
Also, on a side note, this actually isn’t the first time I’ve built a “Blog Platform”. I built a basic one a few years ago in HTML and PHP. Heck, the system I used int he early 2000s with SHTML Pages was sort of a “Blog Platform”.
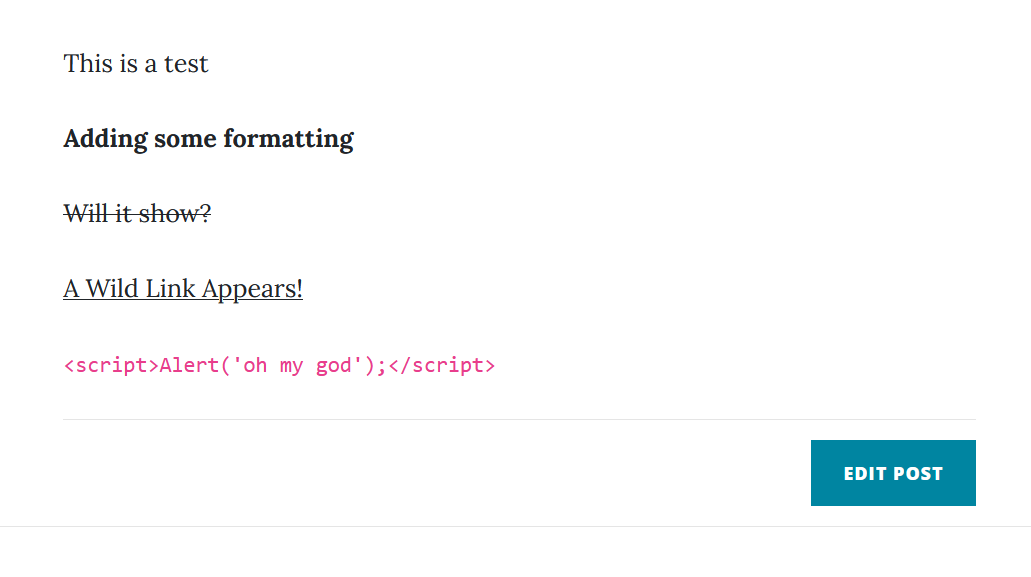
I’d recommend, for anyone going through this course, check the notes on the Blog courses. There are a lot of good suggestions for improvements, especially in stopping things like Java Script injection in the comments. When you go to Angela’s (The Instructor) Blog link, it immediately throws out a JavaScript pop up that someone dropped in the comments.
Day 70 – Hosting with Heroku
So, there isn’t really a Day 70 project. I did go through the section, and the most useful part for me was the more robust SQL solution mentioned in the last section. The first few parts were about GIT and Github, which I am already using. The middle part was about using Heroku, which I have heard of and used a bit before but for the long term, I don’t need to use a freemium hosting service in a jankey way. I have a VPS, and later I will figure out how to get Apache to play nice with Flask.
For now, I’ve split the Blog Project into it’s own repository and worked up my initial planned ToDo List. But I need to keep my focus on the course for now.
Josh Miller aka “Ramen Junkie”. I write about my various hobbies here. Mostly coding, photography, and music. Sometimes I just write about life in general. I also post sometimes about toy collecting and video games at Lameazoid.com.