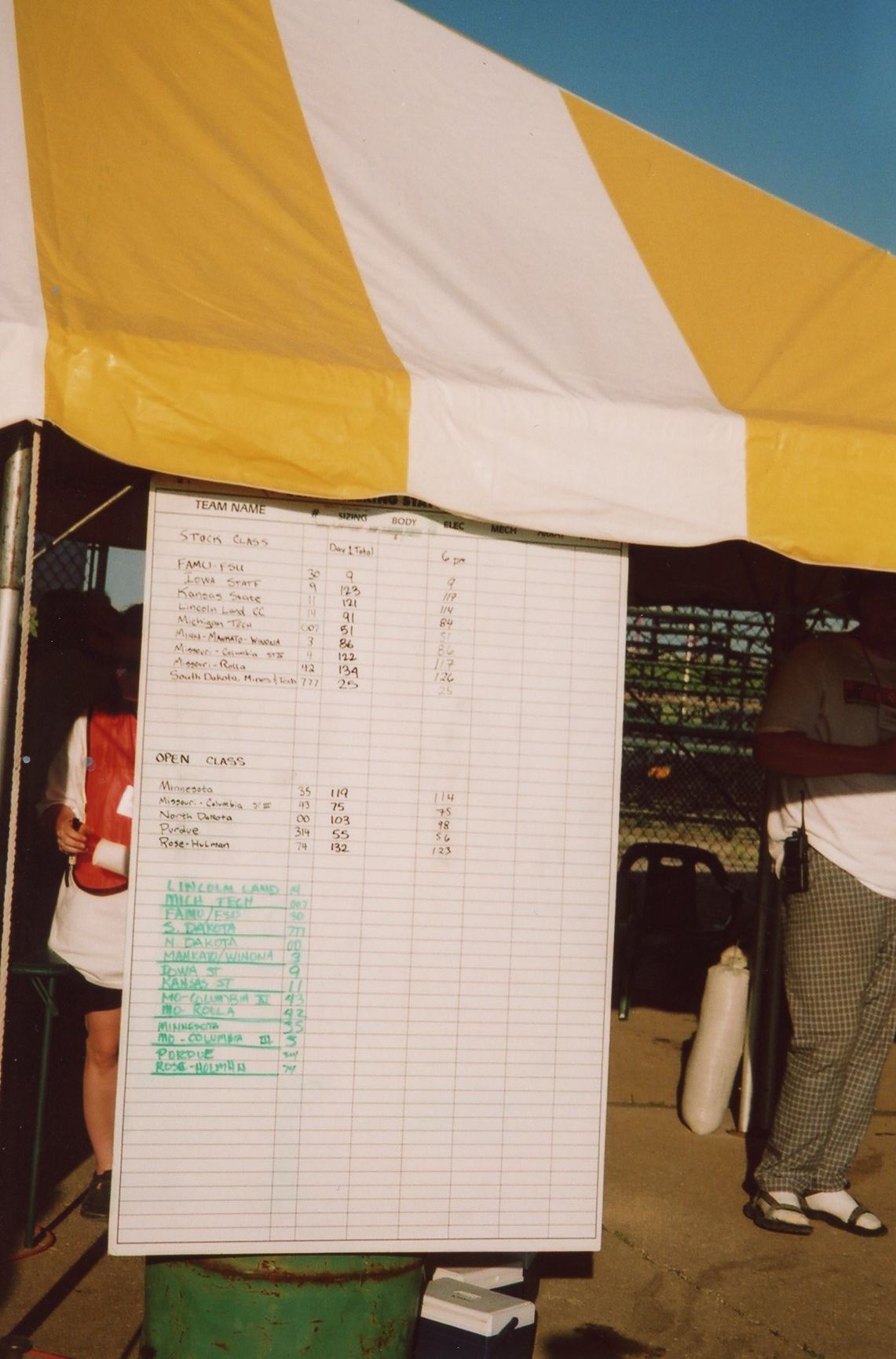
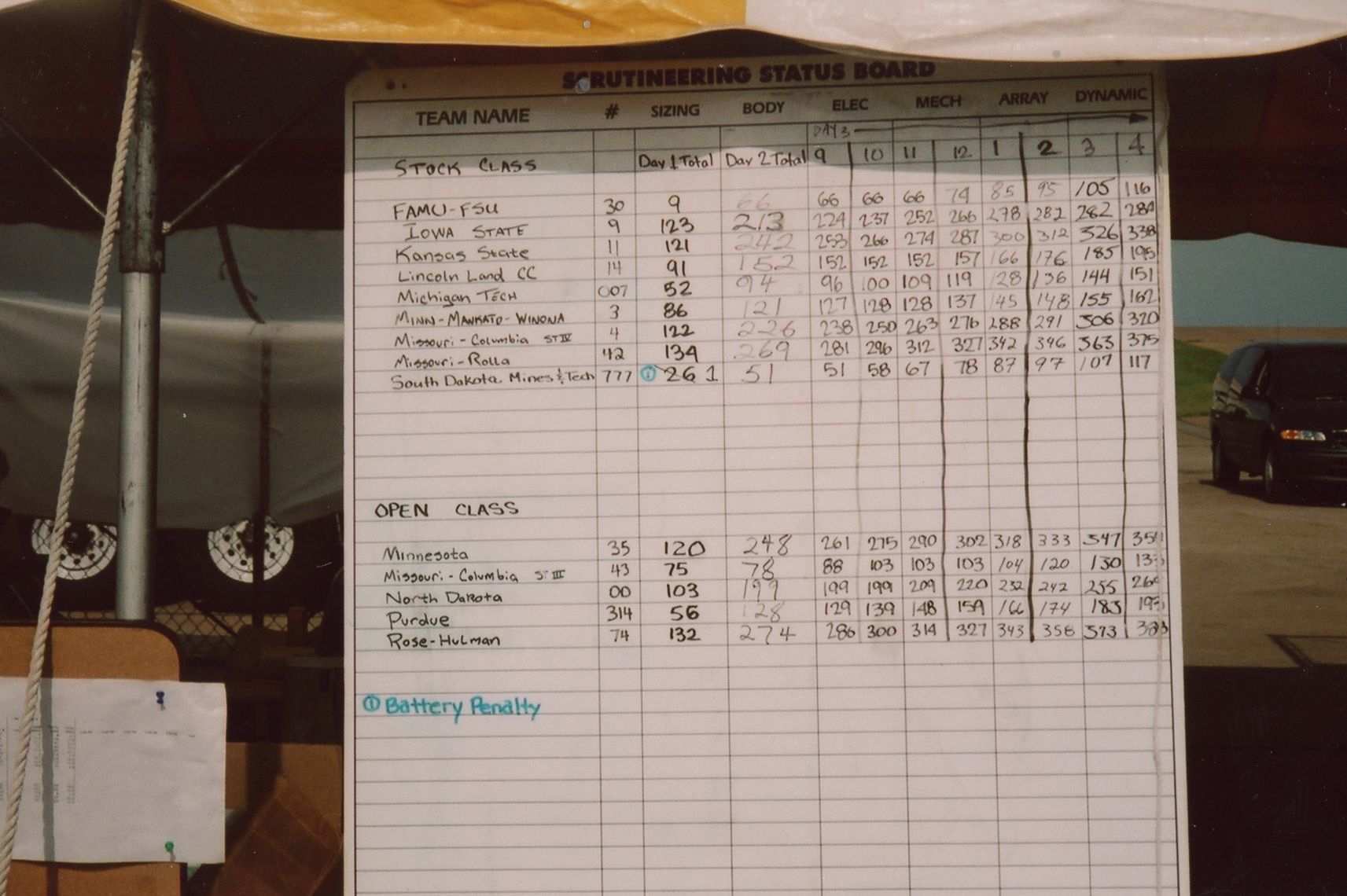
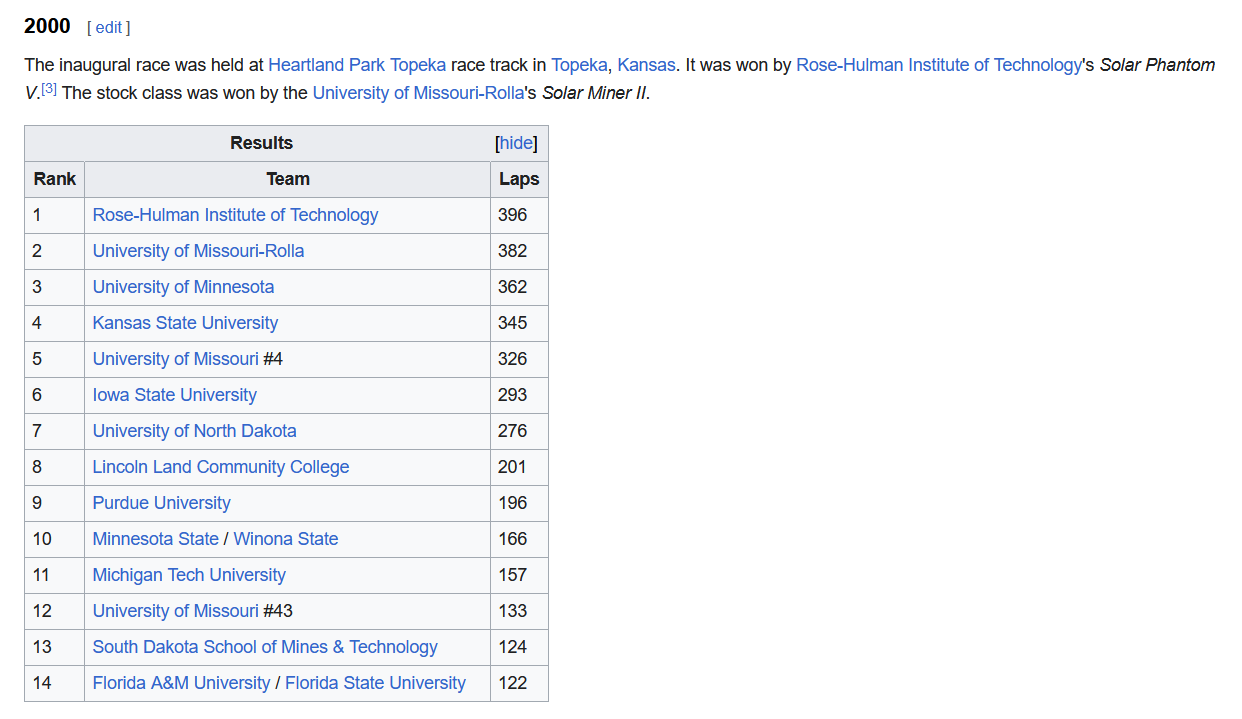
2001 American Solar Challenge LLCC Stop
2001.06.15 – American Solar Challenge stop at Lincoln Land Community College, Springfield, IL































2001.06.15 – American Solar Challenge stop at Lincoln Land Community College, Springfield, IL
May 19-24, 2000 – I was there for the Lincoln Land community College car team.